在人工智能领域,一场无声的革命正在悄然进行。随着2025年的钟声敲响,全球大模型玩家纷纷加速布局,试图在新技术浪潮中占据一席之地。在这场没有硝烟的战争中,MiniMax,作为国内“大模型六小龙”之一,以其独特的战略眼光和技术创新,成为了行业内的焦点。
近年来,大模型行业内部出现了前所未有的分歧。一方面,有人认为基础模型的更新已经陷入停滞,行业创新的重点应转向应用层面;另一方面,有人则坚持认为,技术创新仍是推动行业发展的关键。价格战与价值战的争论也愈演愈烈,同时,单模态与多模态之争也持续升温,对于AGI(通用人工智能)的实现路径,行业内更是众说纷纭。
面对这些分歧,MiniMax选择了自己的道路。自2025年1月以来,MiniMax在短短十天内连续发布了四个AI模型,包括基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01,以及视频模型S2V-01和语音模型T2A-01。尤为引人注目的是,MiniMax首次将两个核心系列模型MiniMax-01进行了开源,这一举动在行业内引起了广泛讨论。
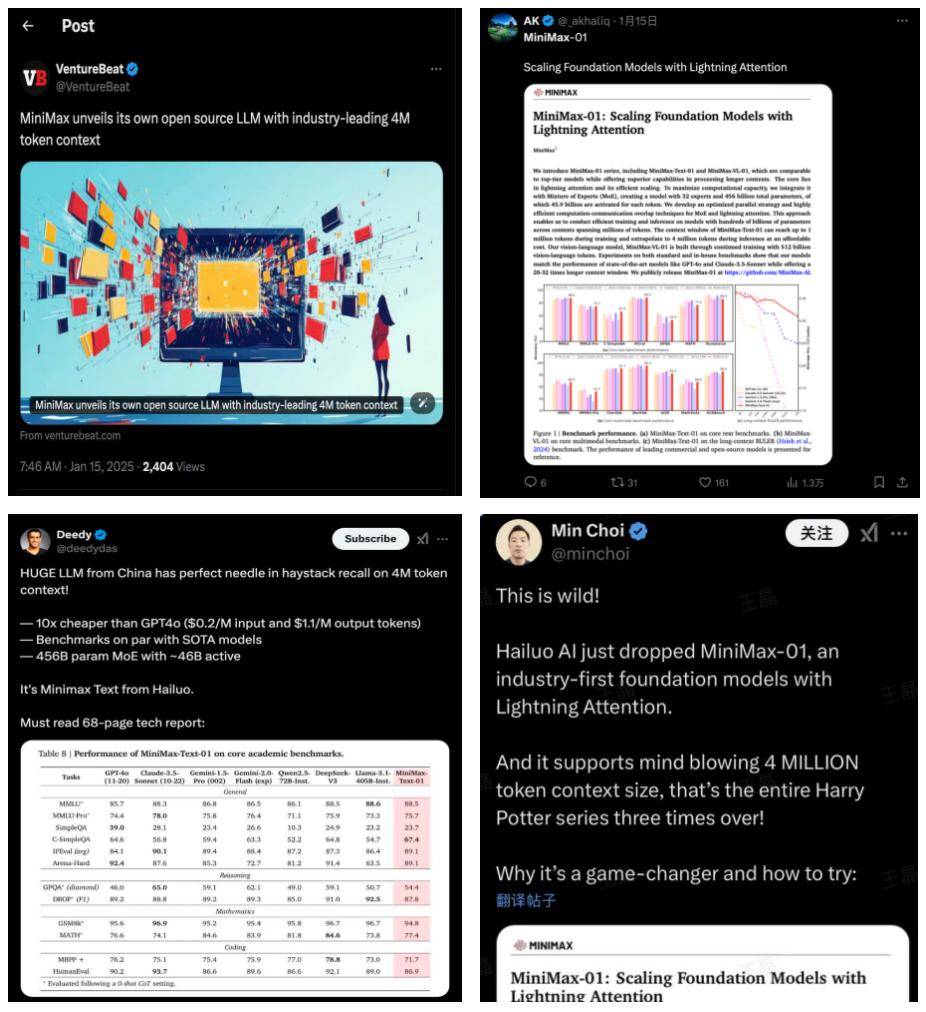
MiniMax的创始人在近期媒体访谈中表示,如果重新选择,公司从一开始就应该选择开源。这一决策背后,是MiniMax试图通过开源、创新和技术驱动的路径,改变市场对其“仅有产品力”的固有印象。MiniMax-01系列模型的发布,更是展示了公司在技术创新方面的决心和实力。
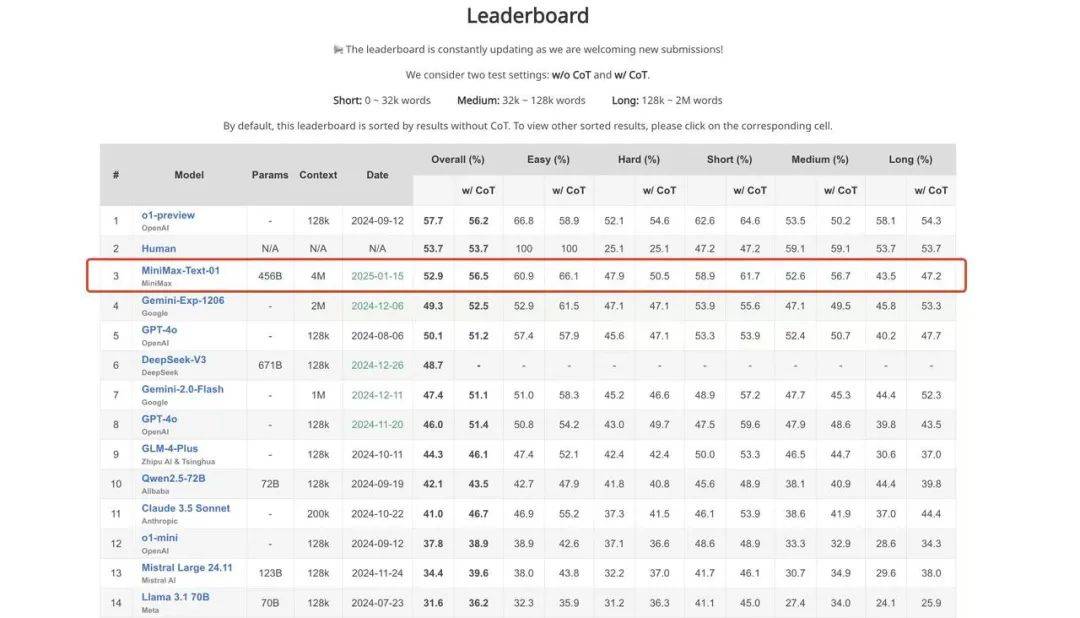
从技术层面来看,MiniMax-01系列模型在参数规模上达到了4560亿,综合性能与业内顶尖模型如GPT-4o、Claude-3.5-Sonnet等持平。更MiniMax-01支持长达400万token的输入,这一数字是GPT-4o的32倍、Claude-3.5-Sonnet的20倍。在测评集LongBench V2的最新结果中,MiniMax-Text-01的综合评分仅次于OpenAI的o1-preview和人类,位列第三。
然而,MiniMax-01的真正亮点并不在于其强大的模型性能,而在于其底层技术的创新。MiniMax首次在一个超大规模商用模型上引入了线性注意力(Linear Attention)机制,这一创新使得模型能够以极低的算力成本,实现与传统Transformer架构相当的性能。这一技术的引入,不仅降低了模型的算力需求,还为困扰整个大模型行业的难题提供了新的解题思路。
在价格战与价值战的争论中,MiniMax选择了后者。面对高昂的算力成本,MiniMax通过技术创新降低了模型的训练与推理成本。其引入的线性注意力技术以及其他一系列优化措施,使得模型在保持高性能的同时,大大降低了算力需求。这一策略不仅使得MiniMax能够在激烈的市场竞争中保持竞争力,还为整个行业提供了有益的借鉴。
在多模态领域,MiniMax同样展现出了强大的实力。其发布的视频模型S2V-01和语音模型T2A-01,不仅在技术上实现了突破,还在应用场景上展现出了广泛的应用前景。S2V-01模型能够打破文生视频和图生视频之间的壁垒,实现更加灵活和自然的视频生成。而T2A-01模型则支持多种语言的语音合成,已经达到了商用水准。

MiniMax在技术创新方面始终保持着独特的眼光和坚定的决心。早在2023年,当国内市场还是稠密模型的天下时,MiniMax就已经将大部分算力和资源投入到了混合专家(MoE)模型的开发中。这一决策在当时看来颇具风险,但如今已经成为业内的共识。同样地,在面对“Transformer撞墙”问题时,MiniMax也选择了通过底层架构的创新来寻求突破。
MiniMax的这些努力不仅得到了市场的认可,还为其赢得了宝贵的用户。其旗下的AI内容社区Talkie已经成为全球第一大AI内容社区,月活跃用户数达到了2977万。这一成就不仅证明了MiniMax在技术创新方面的实力,也为其未来的发展奠定了坚实的基础。