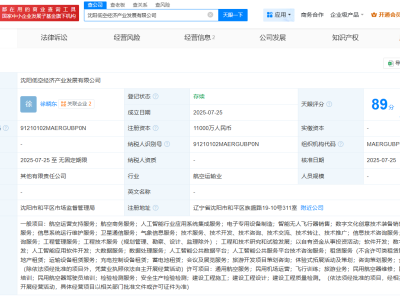
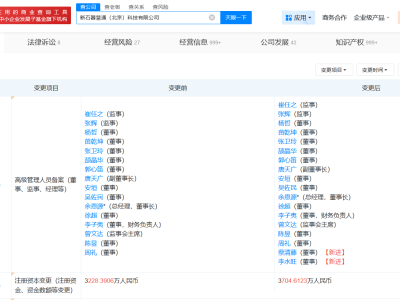
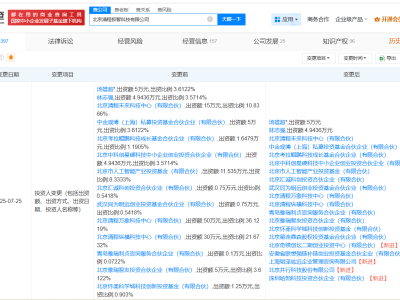
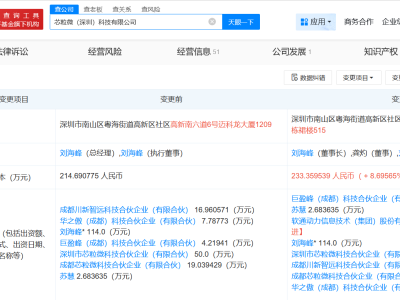
在AI领域,一股新兴势力正悄然崛起。DeepSeek,这一名不见经传的公司,近日凭借其最新的大模型DeepSeek-R1,成功打破了国内大模型的固有格局,成为业界关注的焦点。
1月26日,DeepSeek正式对外发布了其备受瞩目的DeepSeek-R1模型,并慷慨地开源了模型权重。此举遵循了MIT License协议,允许用户借助R1的蒸馏技术,训练出更多样化的模型。这一开放的态度,无疑为AI社区注入了新的活力。
DeepSeek-R1不仅提供了强大的API服务,还允许用户通过设置model='deepseek-reasoner'来调用其独特的思维链输出功能。这一功能使得DeepSeek-R1在处理复杂问题时,能够展现出更加清晰和连贯的推理过程。
DeepSeek-R1之所以能够在短时间内脱颖而出,离不开其在后训练阶段大规模使用强化学习技术的决策。即便在标注数据极为有限的情况下,DeepSeek-R1依然能够显著提升模型的推理能力。在数学、代码、自然语言推理等多项任务上,其性能已经与OpenAI的o1正式版不相上下。
DeepSeek在开源DeepSeek-R1-Zero和DeepSeek-R1两个660B模型的同时,还通过DeepSeek-R1的输出蒸馏出了6个小模型,并将它们开源给了社区。其中,32B和70B模型在多项能力上已经达到了与OpenAI的o1-mini相媲美的水平。
在定价方面,DeepSeek-R1的API服务也展现出了极大的诚意。每百万输入tokens仅需1元(缓存命中)或4元(缓存未命中),而每百万输出tokens也仅需16元。这一价格策略无疑降低了用户的使用成本,进一步推动了AI技术的普及。
DeepSeek的崛起不仅震动了国内AI界,更引起了美国科技界的广泛关注。其性能上的卓越表现以及完全开源的态度,让许多美国科技公司感受到了前所未有的压力。知名投资人马克·安德森更是对DeepSeek-R1给予了高度评价,称其为“最令人惊叹和印象深刻的突破之一”。
AI科技初创公司Scale AI的创始人亚历山大·王也对DeepSeek的成就表示了赞赏。他认为,过去十年里美国一直在人工智能竞赛中领先于中国,但DeepSeek的AI大模型发布可能会改变这一格局。DeepSeek-R1的性能与美国最好的模型相当,甚至在某些方面还更胜一筹。

亚历山大·王进一步指出,DeepSeek-R1的训练计算量比GPT-4o和Claude 3.5 Sonnet减少了10倍,这充分展示了中国在AI技术上的创新能力和效率。他认为,DeepSeek的崛起给美国科技公司敲响了警钟,提醒他们不能掉以轻心。

DeepSeek的动作也让meta的生成式AI团队感到了恐慌。为了应对这一挑战,meta CEO扎克伯格宣布将加速研发Llama 4,并计划投资650亿美元扩建数据中心,部署130万枚GPU。他希望通过这一举措,确保meta AI在2025年成为全球领先的模型。
DeepSeek的崛起无疑给整个AI领域带来了新的竞争格局。如果中国公司能够以更低的成本实现同等或更好的性能,并且这些模型还大都开源,那么美国公司赖以维持的技术优势和高估值可能会受到严峻挑战。这一变革不仅将推动AI技术的进一步发展,也将深刻影响全球科技产业的格局。