在科技日新月异的今天,AI领域迎来了一位崭新的“领跑者”——DeepSeek。2025年1月26日,DeepSeek正式发布其旗舰模型DeepSeek-R1,并慷慨地开源了模型权重,这一举动瞬间在业界掀起了轩然大波。
DeepSeek-R1的问世,无疑打破了国内大模型的固有格局。它不仅性能卓越,在数学、代码、自然语言推理等多个领域展现出与OpenAI o1正式版比肩的实力,更在开源策略上迈出了大胆的一步。遵循MIT License,用户得以通过蒸馏技术,借助R1训练其他模型,这无疑为AI领域注入了新的活力。
为了进一步提升用户体验,DeepSeek-R1还上线了API服务,用户只需通过设置model='deepseek-reasoner',即可轻松调用其强大的思维链输出功能。这一功能的开放,无疑将为用户带来更加智能、高效的AI体验。
DeepSeek-R1的成功并非偶然。在后训练阶段,它大规模使用了强化学习技术,即便在标注数据极少的情况下,也实现了模型推理能力的显著提升。这一技术的运用,无疑为DeepSeek-R1的卓越性能奠定了坚实的基础。
DeepSeek在开源DeepSeek-R1-Zero和DeepSeek-R1两个660B模型的同时,还通过DeepSeek-R1的输出蒸馏了6个小模型并开源给社区。其中,32B和70B模型在多项能力上已实现对标OpenAI o1-mini的效果,这无疑为AI领域的研究者和开发者提供了更为丰富的选择。
DeepSeek的崛起,不仅震动了国内科技界,更引起了美国科技界的广泛关注。知名投资人马克·安德森对DeepSeek R1给予了高度评价,称其为“我见过的最令人惊叹和印象深刻的突破之一”。而AI科技初创公司Scale AI的创始人亚历山大·王更是直言,DeepSeek的AI大模型发布可能会“改变一切”,让美国在人工智能竞赛中的领先地位受到挑战。

DeepSeek的创始人梁文锋,一位在AI领域深耕多年的专家,也因其卓越的贡献而迅速奠定了在AI圈的地位。他本硕均就读于浙江大学信息与电子工程学专业,早年与校友共同创立了幻方量化,并在量化私募领域取得了显著的成就。梁文锋对AI算力的布局和投入,为DeepSeek的快速奔跑提供了坚实的底层支撑。
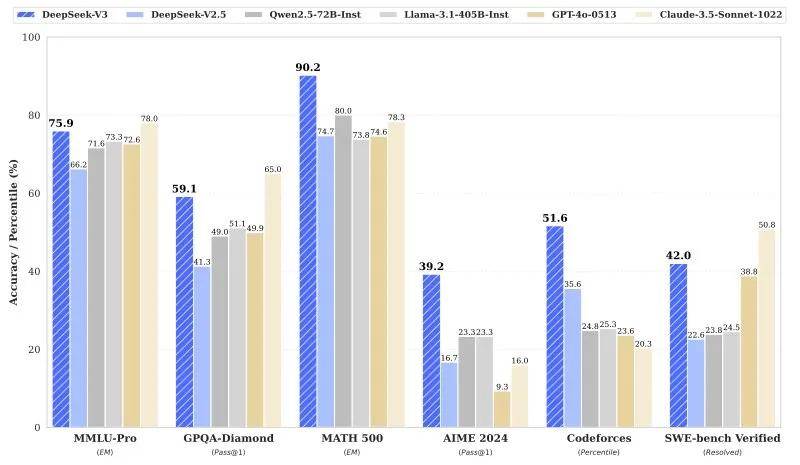
DeepSeek的成功,不仅在于其卓越的性能和开源策略,更在于其背后的工程奇迹。DeepSeek团队在预训练方面取得了显著的突破,通过超强的训练稳定度、深入使用fb8混合精度、多词同时预测等技术,大大降低了训练成本。据称,他们用600万美元就训练出了一个600B的大模型,这一成就无疑为AI领域的研究者和开发者提供了新的思路。
DeepSeek的崛起,无疑将对整个AI领域产生深远的影响。它不仅将推动AI技术的进一步发展,更将引发一系列连锁反应。一些购买了大量NVIDIA芯片的AI初创公司可能会面临破产的风险,而NVIDIA GPU的二手市场或将迎来一波新的浪潮。一些依赖OpenAI API的公司也可能会转向开源,从而降低在AI技术上的支出。