随着春节的脚步日益临近,国产大模型领域迎来了一波新春大礼包,令人目不暇接。百川智能,作为国产大模型领域的佼佼者,近期频繁推出新品,从全场景深度推理模型Baichuan-M1-preview到医疗增强开源模型Baichuan-M1-14B,每一款都引起了业界的广泛关注。
而最新发布的全模态模型Baichuan-Omni-1.5,更是被誉为“大模型通才”,以其全面且强大的能力吸引了众多目光。这款全模态模型不仅能够同时处理文本、图像、音视频等多种模态的理解任务,还支持文本和音频的双模态生成,实现了理解和生成的完美统一。
据测评结果显示,Baichuan-Omni-1.5的多模态能力整体超越了GPT-4o mini。特别是在百川智能深耕的医疗领域,该模型在医疗图片评测上的表现更是大幅领先,展现了其卓越的专业能力。这一成就不仅彰显了百川智能在模型技术探索上的深厚实力,也为其在医疗行业的应用落地奠定了坚实基础。
除了医疗领域,Baichuan-Omni-1.5在音频的理解与生成方面同样表现出色。该模型支持多语言对话,并具备端到端的音频合成能力,包括ASR(自动语音识别)和TTS(文本转语音)功能。在此基础上,它还支持音视频实时交互,进一步提升了用户体验。在音频评测数据集上,Baichuan-Omni-1.5的整体表现也远超其他竞品。
百川智能还开源了两个评测集:OpenMM-Medical和OpenAudioBench,为研究人员和开发者提供了统一的标准数据,有助于催生一系列新的语言理解算法和模型架构。这些举措不仅促进了国内开源生态的繁荣,也为Baichuan-Omni-1.5等全模态模型的应用推广提供了有力支持。
为了实现全模态模型的理解和生成统一,百川智能的研究团队在模型结构、训练策略以及训练数据等多方面进行了全流程的深度优化。在模型结构上,Baichuan-Omni-1.5采用了创新的文本-音频交错输出设计,使得模型能够同时生成文本和音频。同时,为了处理任意分辨率的图片,该模型还引入了NaViT技术,全面提升了图片信息的提取和理解能力。
在数据层面,百川智能构建了包含3.4亿条高质量图片/视频-文本数据和近100万小时音频数据的庞大数据库,并使用1700万条全模态数据进行了监督微调(SFT)。为了加强跨模态理解能力,百川智能还构建了高质量的视觉-音频-文本交错数据,并对模型进行了对齐训练。这些举措共同提升了Baichuan-Omni-1.5的全模态理解和生成能力。
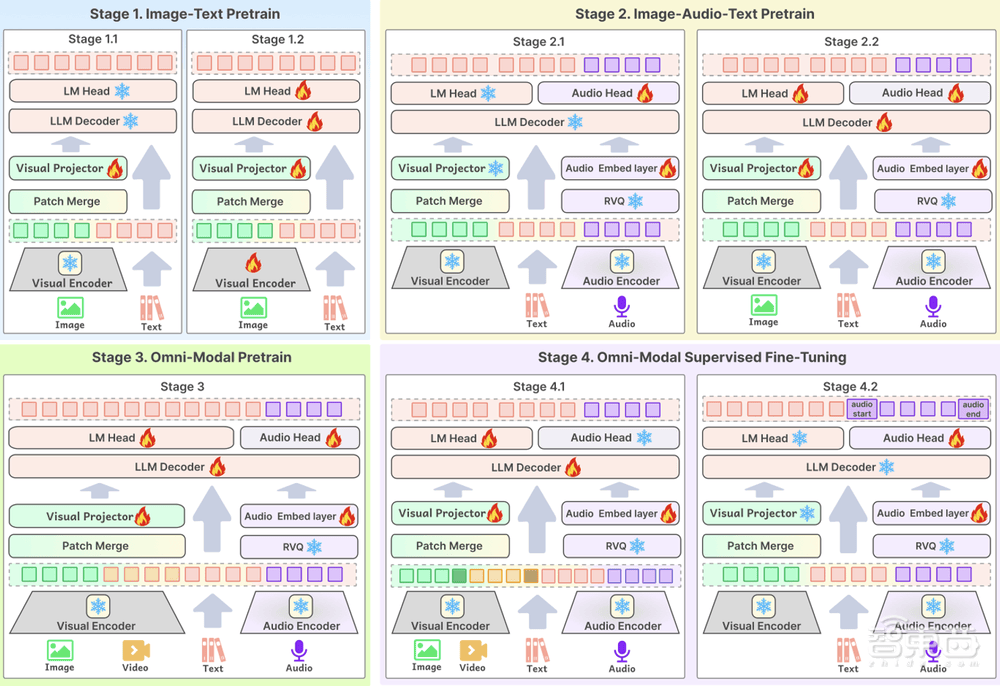
Baichuan-Omni-1.5的发布标志着AI技术正在从模型能力向落地应用方向发展。该模型强大的多模态融合能力将技术与实际场景紧密结合,为各行业的数字化转型提供了有力支撑。特别是在医疗行业,Baichuan-Omni-1.5的理解、生成能力可以用于辅助医生诊断,提高诊断准确性和效率,为AI在医疗场景的应用探索开辟了新的道路。