微软近日宣布了一项重大更新,其OmniParser工具已升级至V2.0版本,这款基于纯视觉的GUI智能体解析工具,专门用于识别和解析屏幕上的可交互图标。通过与GPT-4V等先进模型的结合,OmniParser的识别能力得到了显著提升。
据微软官方消息,OmniParser V2.0在2月12日正式发布。新版本不仅支持OpenAI的多个模型(包括4o、o1、o3-mini),还兼容DeepSeek的R1版本、Qwen的2.5VL版本以及Anthropic的Sonnet模型。这意味着,这些模型现在都可以被转化为能够操控计算机的AI智能体。
与V1版本相比,OmniParser V2.0在训练上采用了更大规模的交互元素检测数据和图标功能标题数据。这一改进使得V2.0在检测较小的可交互UI元素时,不仅准确率更高,而且推理速度更快,延迟降低了60%。这一提升对于提高AI智能体的操作效率和用户体验具有重要意义。
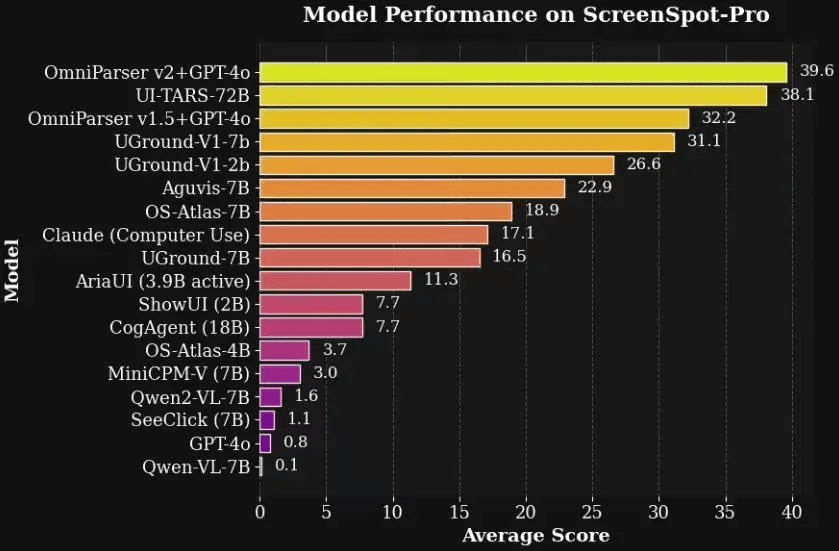
在高分辨率Agent基准测试ScreenSpot Pro中,OmniParser V2.0与GPT-4o的结合展现出了惊人的效果。测试结果显示,V2.0+GPT-4o的准确率高达39.6%,而GPT-4o原始准确率仅为0.8%。这一数据对比充分证明了OmniParser V2.0在提升AI智能体识别能力方面的显著作用。
为了加速不同智能体设置的实验进程,微软还开源了OmniTool这一关键工具。OmniTool是一个集成了智能体所需基本工具的Docker化Windows系统,涵盖了屏幕理解、定位、动作规划和执行等功能。这一工具的推出,无疑为将大模型转化为智能体提供了极大的便利。
对于对OmniParser和OmniTool感兴趣的开发者来说,现在可以通过访问微软在GitHub上的官方仓库来获取这些工具的源代码和相关资源。这一举措不仅展示了微软在推动AI技术发展方面的开放态度,也为全球开发者提供了一个共同学习和进步的平台。







