在迈向通用人工智能(AGI)的征途上,具身智能技术的突破与应用被视为不可或缺的一环。全球科技巨头纷纷加速布局,特斯拉的Optimus、Agility Digit、波士顿动力的Atlas以及Figure AI等机器人项目层出不穷,而在今年的蛇年春晚,机器人“扭秧歌”的趣味表演更是成为了街头巷尾的热门话题。随着大模型技术的不断精进,具身智能迎来了前所未有的发展机遇。
然而,在国内众多企业与高校推动具身智能技术发展的过程中,一个核心挑战始终如影随形——如何在有限的具身数据下,使机器人能够灵活适应复杂场景,并实现技能的高效迁移。为了攻克这一难题,京东探索研究院的李律松、李东江博士团队携手地瓜机器人秦玉森团队、中科大徐童团队、深圳大学郑琪团队、松灵机器人及睿尔曼智能吴波团队,共同发起了一项创新项目。该项目得到了清华RDT团队在baseline方法上的技术支持,旨在探索一种全新的解决方案。
项目团队提出了一种基于三轮数据驱动的原子技能库构建框架,这一创新方法突破了传统端到端具身操作的数据瓶颈。通过该框架,可以动态地自定义和更新原子技能,并结合数据收集与VLA(视觉-语言-动作)少样本学习技术,高效构建技能库。实验结果显示,该方案在数据效率和泛化能力方面均表现出色,为具身智能领域带来了革命性的突破。
具身智能,即让机器人具备身体感知与行动能力的人工智能,在生成式AI时代迎来了重要的发展契机。通过跨模态融合技术,将文本、图像、语音等数据映射到统一的语义向量空间,为具身智能技术的发展提供了新的动力。然而,现实环境的复杂性使得具身操作模型在泛化性上面临巨大挑战。端到端的训练方式虽然直观,但依赖海量数据,容易导致“数据爆炸”问题,限制了VLA技术的发展。
为了解决这一问题,项目团队提出了基于三轮数据驱动的原子技能库构建方法。该方法能够在仿真或真实环境的模型训练中显著减少数据需求。通过VLP(视觉-语言-规划)模型将任务分解为子任务,并利用高级语义抽象模块将子任务定义为通用原子技能集。随着三轮更新策略的动态扩展,技能库不断扩增,覆盖的任务范围也越来越广。这一方法将重点从端到端技能学习转向了细颗粒度的原子技能构建,有效解决了数据爆炸问题,并提升了机器人对新任务的适应能力。
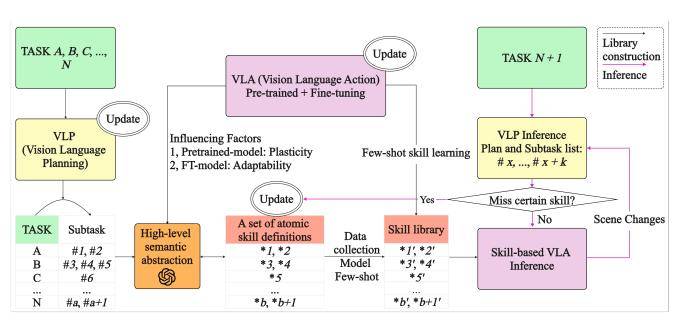
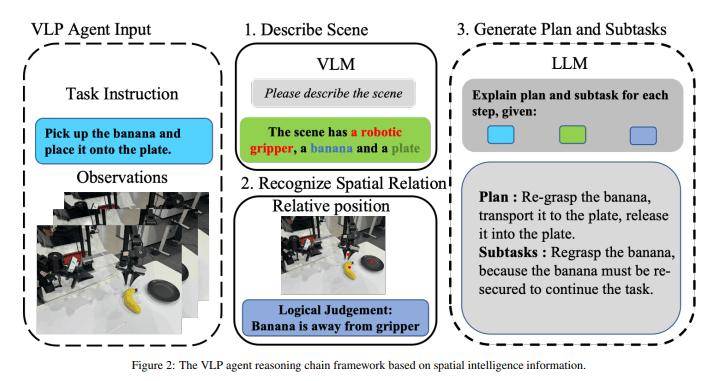
从产业落地角度来看,具身操作是机器人实现智能化的关键模块。然而,现有的端到端VLA模型在进行高频开环控制时,即便中间动作失败,仍会输出下一阶段的控制信号。这导致VLA模型在高频控制机器人或机械臂时,强烈依赖于VLP提供的低频智能控制来指导阶段性动作生成,并协调任务执行节奏。为此,项目团队构建了集成视觉感知、语言理解和空间智能的VLP Agent,以统一训练与推理的任务分解。
VLA技术虽然取得了显著进展,但仍存在一些问题。随着技术的发展,VLA模型从专用数据向通用数据演进,机器人轨迹数据已达百万级别;模型参数规模也从千亿级向端侧部署发展。然而,在通用机器人应用中,人为定义端到端任务容易导致任务穷尽问题。物品位置泛化、背景干扰、场景变化等仍是主要挑战。即便强大的预训练模型,也需要大量数据来克服这些问题。项目团队提出的三轮数据驱动的原子技能库方法,结合SOTA VLA模型,通过高级语义抽象模块将复杂子任务映射为结构化原子技能,有效提升了VLA模型的泛化性和可塑性。

原子技能库的构建旨在降低数据采集成本,同时增强任务适配能力,提升具身操作的通用性,以满足产业应用需求。通过基于数据驱动的原子技能库构建方法,结合端到端具身操作VLA与具身规划VLP,项目团队成功构建了一个系统化的技能库。这一技能库能够动态扩增,适应的任务范围也不断增加。相比传统的TASK级数据采集,提出的原子技能库所需要的数据采集量显著下降,同时技能适配能力得到了大幅提升。










