近期,一项关于合成数据在大型模型训练中应用的新研究成果引起了业界的广泛关注。这项研究由谷歌、卡内基梅隆大学和MultiOn的联合研究团队共同完成。
据Epoch AI的研究报告显示,尽管全球范围内已有约300万亿个高质量的文本训练标记可供使用,但随着ChatGPT等大模型的快速发展,对训练数据的需求正呈爆炸式增长。预测显示,到2026年,现有的高质量训练数据或将无法满足需求。因此,探索合成数据作为替代方案显得尤为重要。
在此次研究中,研究人员主要聚焦于两种类型的合成数据:正向数据和负向数据。正向数据由高性能大模型(例如GPT-4和Gemini 1.5 Pro)生成,提供正确的数学问题解决方案,为模型提供学习范例。然而,单纯依赖正向数据存在局限性,可能导致模型仅通过模式匹配学习,缺乏真正的理解能力,且在处理新问题时泛化能力下降。
为了克服这些挑战,研究人员引入了负向数据,即经过验证的错误问题解决步骤。负向数据的加入有助于模型识别并避免错误,从而提升其逻辑推理能力。尽管使用负向数据面临诸多困难,如错误步骤可能包含误导性信息,但研究团队通过直接偏好优化(DPO)方法成功使模型能够从错误中学习。
DPO方法为每个问题解决步骤分配一个优势值,反映其相对于理想解决方案的价值。研究表明,高优势步骤是正确解决方案的关键,而低优势步骤则可能揭示模型推理中的问题。借助这些优势值,模型能够在强化学习框架内动态调整策略,更高效地从合成数据中学习和改进。
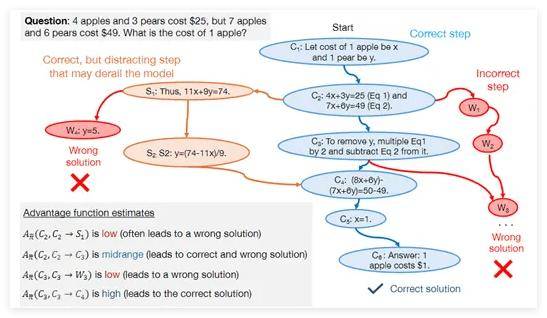
为了验证合成数据的有效性,研究团队选择了DeepSeek-Math-7B和LLaMa2-7B等模型,在GSM8K和MATH数据集上进行了全面测试。测试结果显示,经过正向和负向合成数据预训练的大模型在数学推理任务上的性能实现了显著提升,甚至达到了八倍的增长。这一研究成果充分展示了合成数据在增强大模型逻辑推理能力方面的巨大潜力和实际应用价值。







