在近日举办的2025英特尔具身智能解决方案推介会上,英特尔正式揭晓了其具身智能大小脑融合方案,这一创新方案基于英特尔酷睿Ultra处理器以及全新的具身智能软件开发套件和AI加速框架,旨在满足多样化领域的需求。
具身智能产品目前正处于小批量阶段,不同应用场景对IO接口、传感器和算力提出了不同要求。如何快速适配这些需求,打造一个灵活且高效的计算平台,成为当前面临的关键挑战。英特尔推出的方案采用了一体化单系统设计,相较于传统的双系统方案,能够以更低的总成本实现工作负载的高效灵活分配。

硬件方面,该方案搭载了英特尔酷睿Ultra CPU核心板。其中,英特尔酷睿Ultra 200H CPU提供高达90 TOPS的性能,而下一代Panther Lake的算力更是可达180 TOPS。其模块化设计允许针对不同应用场景进行灵活搭配,如支持MxM嵌入式显卡插槽以接入英特尔锐炫独立显卡,摄像头转接板可接入多路MIPI/GMSL嵌入式摄像头,增强感知能力,独立的IO载板则用于扩展各类接口。
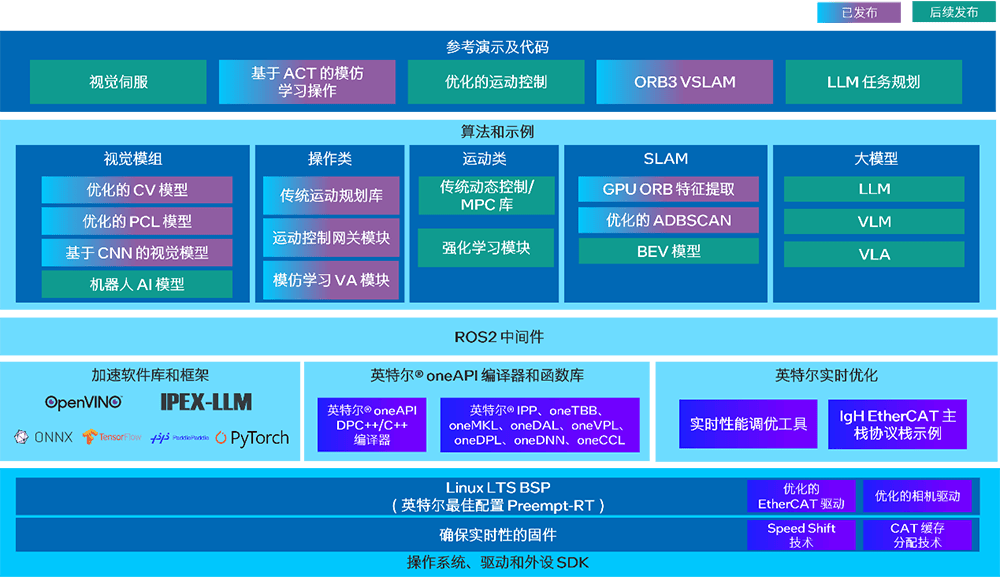
软件层面,该方案提供了全栈式软件平台,涵盖底层的BSP、算法模型、加速库和参考示例等,并附带详细的文档和开发教程。还提供了实时调优BKC、RT Linux内核以及优化的EtherCAT IgH主站协议栈示例,以更好地支持实时运动控制。算法方面,英特尔对CPU上的传统运动规划和视觉算法进行了优化,并通过iGPU和NPU加速基于深度学习和大模型的感知和操作。
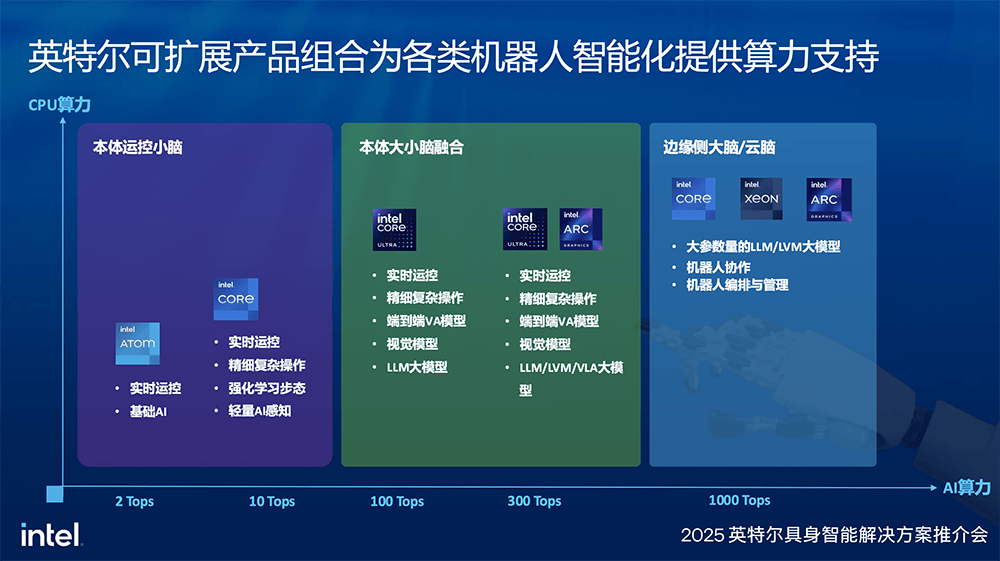
英特尔的方案在算法优化和软件开发工具方面也颇具特色,包括实时性能调优工具和Debug工具,这些工具有助于降低学习成本和开发部署成本。英特尔丰富的可扩展产品组合,从入门级到1000TOPS以上的AI算力,以及从低到高的CPU算力产品组合,使得构建各种类型的具身智能解决方案成为可能。
英特尔酷睿Ultra产品线将CPU、GPU、NPU封装在一个SoC中,使得低功耗SoC能够提供强劲的CPU算力和AI算力,满足具身智能在大多数场景的需求。不同系统之间通过共享内存进行通信,这种方式相较于传统的网络通信更为稳定且快速。单系统方案还显著降低了整体计算成本,提高了能效,并支持更小巧的尺寸和灵活的接口设计。
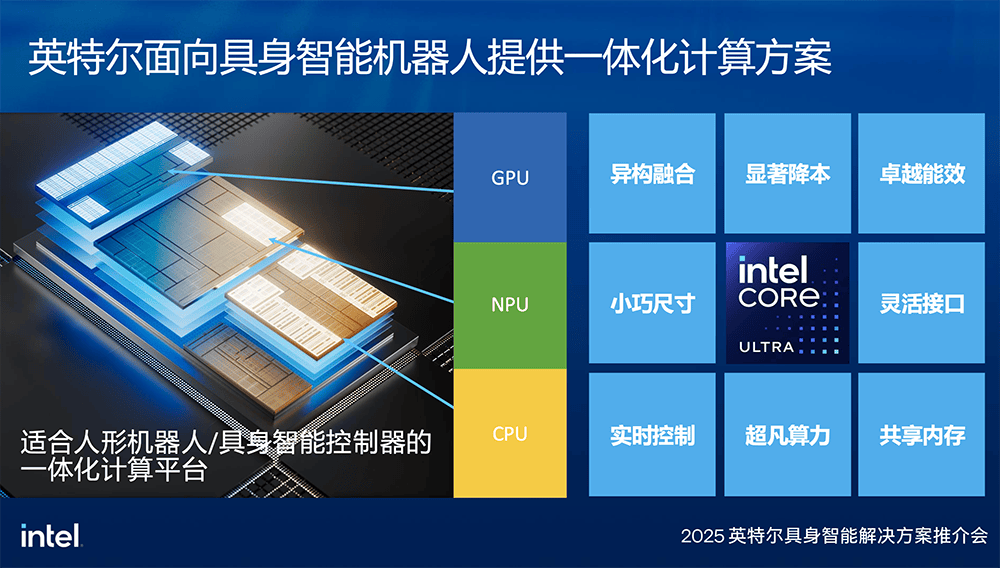
以大小脑融合为亮点,英特尔的具身智能方案实现了感知、交互、任务规划和运动控制在统一系统中的高效整合。酷睿Ultra处理器作为算力中枢,通过CPU、集成的英特尔锐炫GPU与NPU协同工作,支持具身智能多样化负载的稳定运行,并大幅提升整体效率和响应能力。CPU支持复杂的运动控制,GPU处理环境感知、任务识别、大语言模型等任务,而NPU则负责语音识别、实时视觉处理等AI任务。
英特尔还推出了具身智能软件开发套件,包含OpenVINO工具套件、英特尔oneAPI工具包、Intel Extension for PyTorch-LLM(IPEX)等,旨在缩短评估和开发时间,加快客户应用程序的部署以及算法和应用的运行。该套件能够将不同类型的工作负载均匀分配到CPU、NPU、集成显卡甚至独立显卡上,实现计算资源的充分利用。
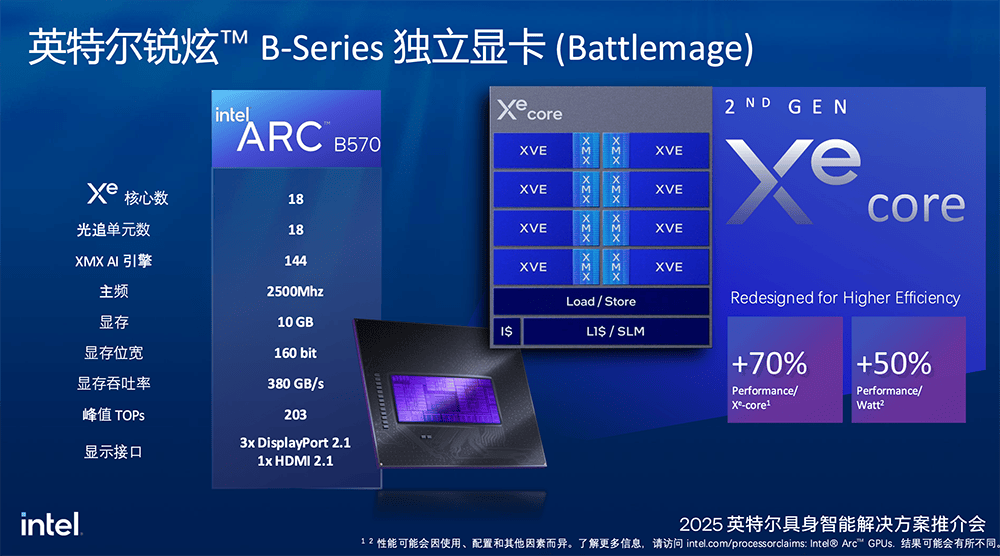
英特尔与本地生态伙伴展开了深度合作,探索从技术研发到场景落地的全链路协同模式。例如,信步科技推出的具身智能硬件开发平台HB03,搭载英特尔酷睿Ultra 200系列处理器和英特尔锐炫B570显卡,提供强大且灵活的算力,并实现极强的控制实时性。HB03具有性能更强、尺寸更小、可靠性更高、灵活配置等优势,为具身智能“大小脑”融合提供了有力的硬件支撑。