阿里巴巴在技术创新领域再次迈出重要一步,于近日凌晨正式发布了其最新一代的通义千问模型——Qwen3。这一发布不仅标志着阿里巴巴在人工智能领域的深厚积累,更让Qwen3一跃成为全球最顶尖的开源模型。
Qwen3系列模型涵盖了多个版本,从Qwen3-0.6B到Qwen3-32B,以及更高级的MoE模型Qwen3-30B-A3B和Qwen3-235B-A22B,它们在层数、头数、嵌入绑定、上下文长度等关键指标上展现出不同的配置。其中,Qwen3-235B-A22B作为旗舰模型,在代码、数学、通用能力等基准测试中,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比,展现出了卓越的性能。
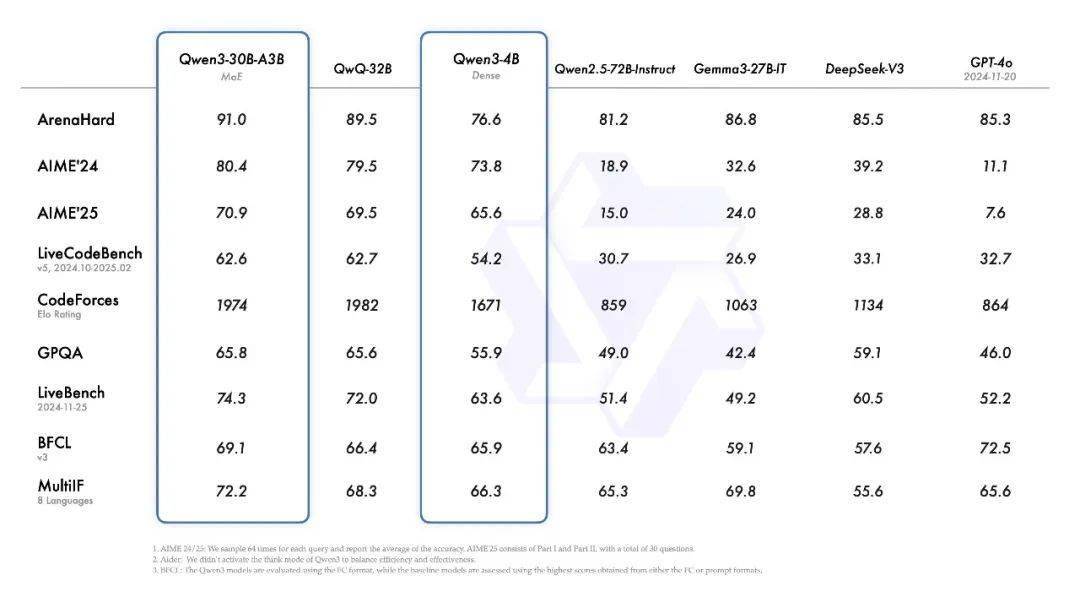
Qwen3是国内首个“混合推理模型”,它将“快思考”与“慢思考”巧妙融合于一个模型中,实现了算力消耗的极大节省。这种设计使得Qwen3能够在面对复杂问题时进行深入推理,而在处理简单问题时则能提供快速响应。
阿里云不仅开源了Qwen3的MoE模型权重,包括Qwen3-235B-A22B和Qwen3-30B-A3B,还开源了六个Dense模型,这些模型均在Apache 2.0许可下开放给公众使用。这一举措无疑将极大地推动人工智能技术的发展和应用。
Qwen3模型支持多达119种语言和方言,这一广泛的多语言能力为全球用户提供了前所未有的便利。无论是简体中文、繁体中文还是粤语,Qwen3都能轻松应对,为国际应用开辟了全新的可能性。
在预训练方面,Qwen3的数据集相比前代Qwen2.5有了显著扩展。Qwen3使用了约36万亿个token的数据进行预训练,涵盖了119种语言和方言。这些数据不仅来自网络,还包括从PDF文档中提取的文本信息。为了增加数学和代码数据的数量,阿里云还利用Qwen2.5-Math和Qwen2.5-Coder这两个专家模型合成了大量数据。

Qwen3的预训练过程分为三个阶段,每个阶段都针对不同的目标和数据集进行优化。在第一阶段,模型在超过30万亿个token上进行了基础预训练;在第二阶段,通过增加知识密集型数据的比例来改进数据集,并在额外的5万亿个token上进行了预训练;在第三阶段,使用高质量的长上下文数据将上下文长度扩展到32K token,以确保模型能够处理更长的输入。
在后训练方面,阿里云实施了一个四阶段的训练流程,旨在开发同时具备思考推理和快速响应能力的混合模型。这一流程包括长思维链冷启动、长思维链强化学习、思维模式融合和通用强化学习四个阶段。
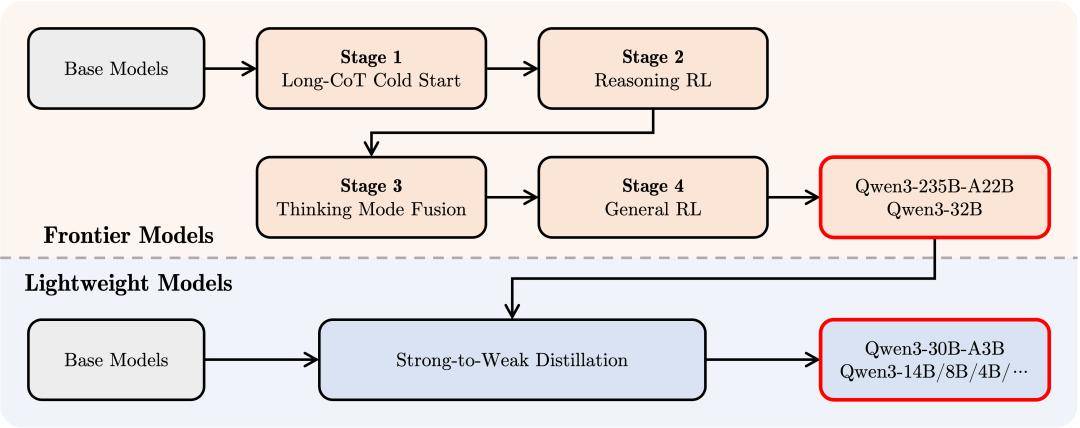
阿里云还为部署用户提供了一种软切换机制,允许用户在enable_thinking=True时动态控制模型的行为。用户可以通过添加/think和/no_think指令来逐轮切换模型的思考模式,这一功能在多轮对话中尤为实用。

目前,用户可以在Qwen Chat网页版(chat.qwen.ai)和通义App中试用Qwen3模型,体验其强大的功能和灵活的思考模式。这一创新不仅将推动人工智能技术的进一步发展,也将为全球用户带来更加便捷和智能的服务。