阿里云正式推出了其通义大模型家族的新成员——Qwen3系列,这一消息在科技圈内迅速引发了广泛关注。在4月29日凌晨4点,阿里云宣布将Qwen3系列模型全面开源,涵盖了2个MoE模型和6个稠密模型,短时间内就在GitHub上收获了超过16.9k的星标。
旗舰模型Qwen3-235B-A22B在多项基准测试中表现突出,特别是在编程、数学和通用能力方面,超越了DeepSeek-R1、OpenAI o1、OpenAI o3-mini、Grok-3和Gemini-2.5-Pro等知名模型。这一成就标志着Qwen3系列在智能水平上迈出了重要一步。
Qwen3系列此次升级带来了五大核心特性。首先,提供了从0.6B到Qwen3-235B-A22B(2350亿总参数和220亿激活参数)等多种参数规模的稠密与MoE模型,满足了不同场景下的应用需求。其次,引入了混合思考模式,用户可以根据需要切换“思考模式”和“非思考模式”,灵活控制模型的思考程度。
在推理能力方面,Qwen3系列在数学、代码生成和常识逻辑推理方面超越了QwQ(在思考模式下)和Qwen2.5 instruct models(在非思考模式下)。Qwen3系列还支持MCP(模型上下文协议),增强了Agent能力,能够在思考和非思考模式下实现大语言模型与外部数据源和工具的集成,完成复杂任务。最后,Qwen3系列支持多达119种语言和方言,具备强大的多语言理解和生成能力。

Qwen3系列模型已在Hugging Face、ModelScope和Kaggle等平台上开源,并遵循Apache 2.0许可证。阿里云建议开发者使用SGLang和vLLM等框架进行部署,并推荐本地部署的开发者使用Ollama、LMStudio、MLX、llama.cpp等工具。Qwen3系列采用了新的命名方案,后训练模型不再使用“-Instruct”后缀,基础模型的后缀改为“-Base”。
在性能表现上,Qwen3系列同样令人瞩目。小型MoE模型Qwen3-30B-A3B在激活参数仅为QwQ-32B的十分之一的情况下,实现了性能反超。同时,参数规模更小的Qwen3-4B模型也展现出了与Qwen2.5-72B-Instruct相当的性能。这一成果得益于Qwen3系列在预训练数据集和训练方法上的全面优化。
Qwen3系列的预训练数据集大小是Qwen2.5的两倍,达到了约3600亿个token。为了构建这一大型数据集,研发人员收集了网络数据、PDF文档数据等,并使用Qwen2.5-VL和Qwen2.5等模型进行文本提取和质量提升。预训练过程分为三个阶段,逐步提升了模型的基本语言技能、一般知识以及处理长输入的能力。
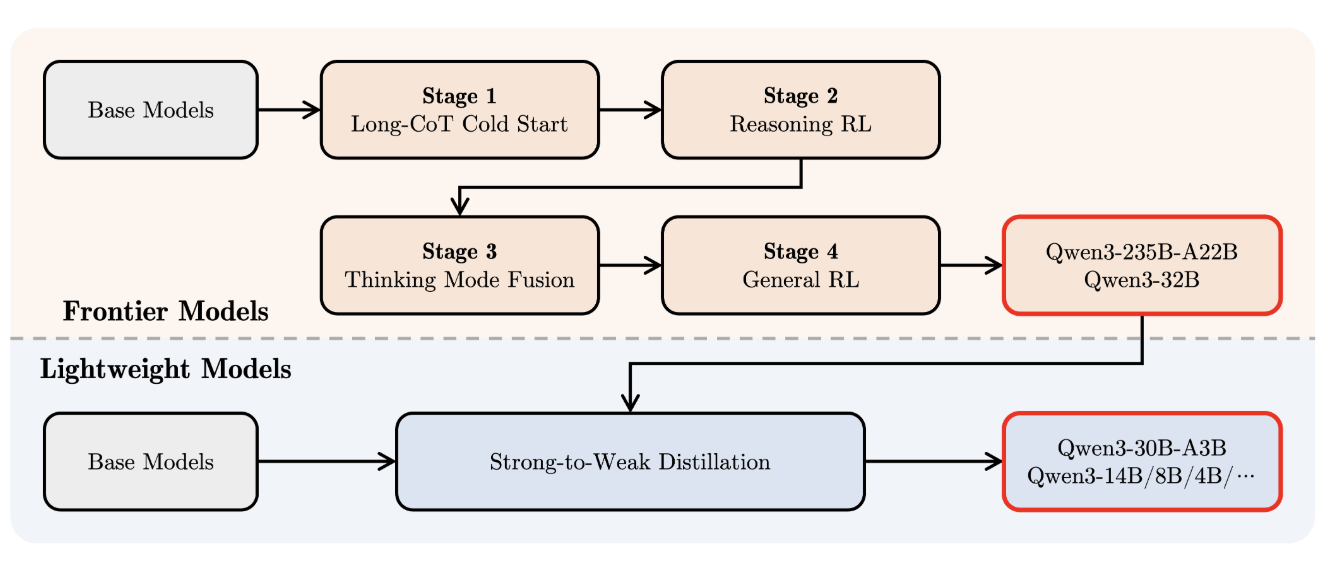
在后训练阶段,研发人员采取了四阶段训练流程,旨在开发既能逐步推理又能快速响应的混合模型。通过多样化的长思维链数据微调、基于推理的强化学习、思维模式融合以及通用强化学习等步骤,Qwen3系列成功实现了推理能力和快速响应能力的无缝融合。
随着AI产业的不断发展,大模型能力的实际应用价值逐渐凸显。阿里云推出的Qwen3系列模型,以其卓越的性能和灵活的应用特性,为AI技术的应用注入了新的活力。未来,Qwen3系列将继续在优化模型架构和训练方法等方面不断探索,推动智能水平的进一步提升。







