在人工智能界,一场静悄悄的变革在深夜悄然上演。此次的主角,是以快速迭代著称的阿里巴巴,其最新推出的Qwen3系列大模型,如同一颗重磅炸弹,直接震撼了整个行业,矛头直指DeepSeek等顶尖选手,甚至对Gemini 2.5 Pro构成了强有力的挑战。更为引人注目的是,Qwen3不仅是全球首个开源的混合推理模型,还支持119种语言和方言,同时兼容MCP协议,一经发布便迅速登顶全球开源模型排行榜。
这一消息迅速在开发者社区引发热烈反响,讨论热度直线飙升。Qwen3此次带来的“豪华套餐”,打破了传统单一参数模型的局限,创新性地推出了两种类型的模型组合。
首先亮相的是MoE(混合专家)模型,包括旗舰款Qwen3-235B-A22B,总参数超过2350亿,但实际激活参数仅为220亿多,性能卓越;另一款则是小巧而高效的Qwen3-30B-A3B,总参数300亿,激活参数仅30亿。MoE模型的工作原理类似于聘请了一群专家,只在需要时调用最相关的几位,大大提高了工作效率。
紧接着是Dense(密集)模型系列,共六款不同规模的模型,从Qwen3-32B到Qwen3-0.6B,覆盖了各种算力需求,展现了极高的能效比。
在性能方面,旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中均表现出色。尤其值得一提的是效率的提升,如30B的MoE模型Qwen3-30B-A3B,仅凭相当于32B Dense模型10%的激活参数,便实现了更优的性能。
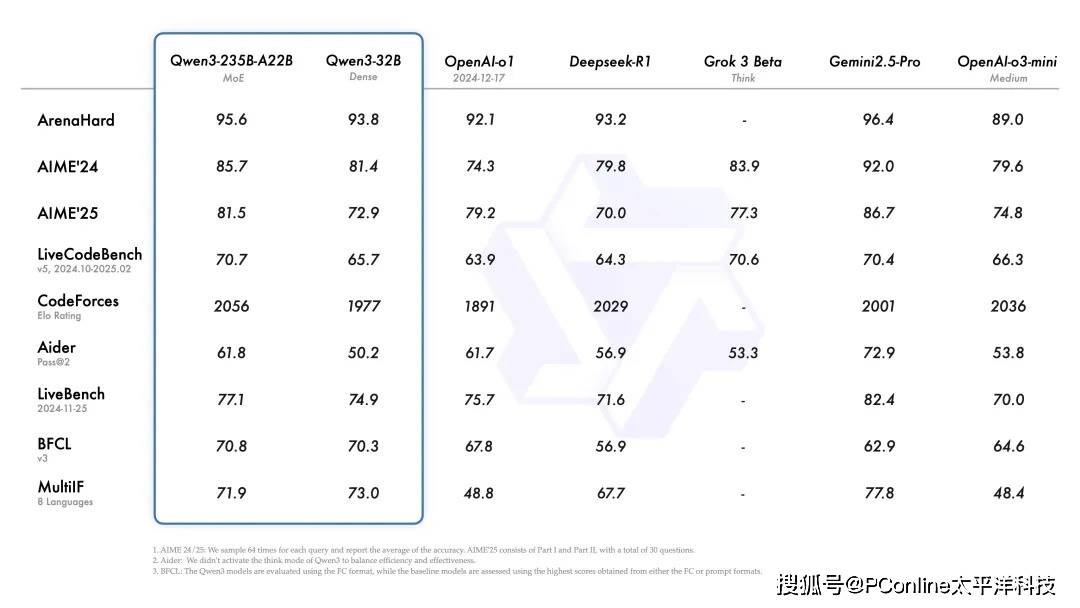
即便是小模型Qwen3-4B,其性能也能与上一代Qwen2.5-72B-Instruct相媲美,实现了资源的高效利用。Qwen3的Dense模型在同等尺寸下,整体性能也超越了参数量更大的Qwen2.5同类模型,尤其在数理、代码、推理方面表现更为突出。
Qwen3的核心竞争力不仅在于参数的提升,更在于其创新的双重思考模式。面对复杂问题时,模型会进行深入推理,宛如“老教授”;而面对简单问题时,则迅速响应,追求极致效率。用户还可以根据需求动态切换思考模式,实现对模型“思考预算”的精细化管理。
全球化视野也是Qwen3的一大亮点,支持119种语言和方言,真正实现了无障碍沟通。其Agent能力也得到显著提升,支持MCP协议,在工具调用和代码执行方面进行了优化,使其更擅长作为“智能助理”与环境交互解决问题。
最令开发者兴奋的是,Qwen3系列模型现已全部开源,包括预训练基础模型和后训练的对话模型,用户可通过Hugging Face、魔搭社区(ModelScope)、Kaggle等主流平台免费下载并进行商业使用。阿里云百炼平台也提供了API调用服务,推荐使用SGLang、vLLM等框架进行部署。对于希望在本地体验的用户,也有多种工具可供选择。
普通用户则可通过通义官网或app直接体验Qwen3的智能魅力,夸克也将很快接入。尽管从普通用户视角来看,各大模型的表现可能相差无几,但Qwen3在背后的资源调用和优化方面展现出了独特优势。
回顾Qwen系列的发展历程,从初出茅庐的Qwen1.0到如今的Qwen3.0,每一步都充满了挑战与不易。在全球AI领域的“百模大战”中,Qwen系列能够脱颖而出,不仅得益于雄厚的资金投入和顶尖的技术积累,更在于其清晰的战略定力和坚持开源的魄力。

从追赶到并跑,甚至在某些方面开始领跑,Qwen系列的发展是中国AI力量崛起的一个生动写照。它告诉我们,在科技前沿领域,只要有持续的投入、正确的方向和足够的韧性,就能不断创造奇迹,引领未来。



