在人工智能领域,尽管现有的顶尖大语言模型(SOTA)展现了卓越智能,部分任务表现甚至超越人类,但其庞大的参数规模——动辄数千亿乃至万亿级别,导致了高昂的训练、部署及推理成本。对于企业及开发者而言,在处理相对简单却需大规模、高并发处理的任务时,这些顶尖模型并非性价比最优的选择。
针对这一痛点,新兴初创公司Fastino应运而生。该公司利用低端游戏GPU,以平均不足10万美元的成本,成功训练出一系列名为“任务特定语言模型”(TLMs)的小型模型。这些模型在特定任务上的性能可媲美大型语言模型,且推理速度快了99倍。
近期,Fastino宣布获得由Khosla Ventures领投的1750万美元种子轮融资,Insight Partners、Valor Equity Partners及知名天使投资人Scott Johnston(前Docker首席执行官)和Lukas Biewald(Weights & Biases首席执行官)参与跟投。加上2024年11月由M12(微软旗下)和Insight Partners领投的700万美元前种子轮融资,Fastino累计融资额已近2500万美元。
Fastino由连续创业者Ash Lewis(首席执行官)和George Hurn-Maloney(首席运营官)共同创立。Ash Lewis此前还参与创立了DevGPT、Ashtv AI等多家AI原生公司。他们组建了一支技术团队,成员来自谷歌DeepMind、斯坦福大学、卡内基梅隆大学及苹果等顶尖机构,能够从底层技术革新,训练出“任务特定语言模型”。

Fastino的TLM模型在成本效益和性能上表现突出。随着AI模型规模的不断扩大,虽然数千亿至上万亿参数的SOTA模型在智能上持续提升,甚至在某些初级任务上替代人力,但高昂的训练、部署及推理成本使得它们在经济性上并不总是最优选择。即便是拥有近10亿周活用户的OpenAI,也面临着用户增长带来的成本飙升压力。
Ash Lewis谈及创业初衷时表示:“我们上一家创业公司在走红后,基础设施成本急剧上升。有一段时间,语言模型的开支甚至超过了整个团队的费用,这促使我们创立了这家公司。”
除了高昂的运行成本,大尺寸模型的通用性与专用性之间的矛盾也是一大问题。虽然大尺寸模型带来了强大的智力和通用性,但在特定专用任务上性能可能并不突出,且需为通用性支付额外成本。大尺寸模型运行速度慢,影响了用户体验。当前的AI工作负载更看重精准度、速度和可扩展性,而非泛化的推理能力。
George Hurn-Maloney指出:“AI开发者不需要在无数无关数据点上训练的大语言模型,他们需要适合其任务的正确模型。因此,我们推出了高精度、轻量化的模型,让开发者能够无缝集成。”
Fastino的TLMs专为需要低延迟、高精度AI的开发者和企业设计,不针对消费级用户,无需通用性。这些模型结合了基于Transformer的注意力机制,并在架构、预训练和后训练阶段引入任务专精。它们优先考虑紧凑性和硬件适应性,同时不牺牲任务准确性。这种架构和技术创新使得TLM模型能够在低端硬件上高效运行,同时提升任务准确性。
相比OpenAI GPT-4o的4000ms延迟,Fastino的TLM模型延迟低至100ms,快了99倍。在性能方面,Fastino对比了TLM模型在意图检测、垃圾信息过滤、情感倾向分析、有害言论过滤、主题分类和大型语言模型防护等基准上的表现,结果显示其F1分数比GPT-4o高出17%。

Fastino的TLM模型并非单一模型,而是针对每个特定用例训练的一组模型。首批模型能够应对一些需求最明确且广泛的企业和开发者核心任务,如文本摘要、函数调用、文本转JSON、个人身份信息屏蔽、文本分类、脏话过滤和信息提取等。
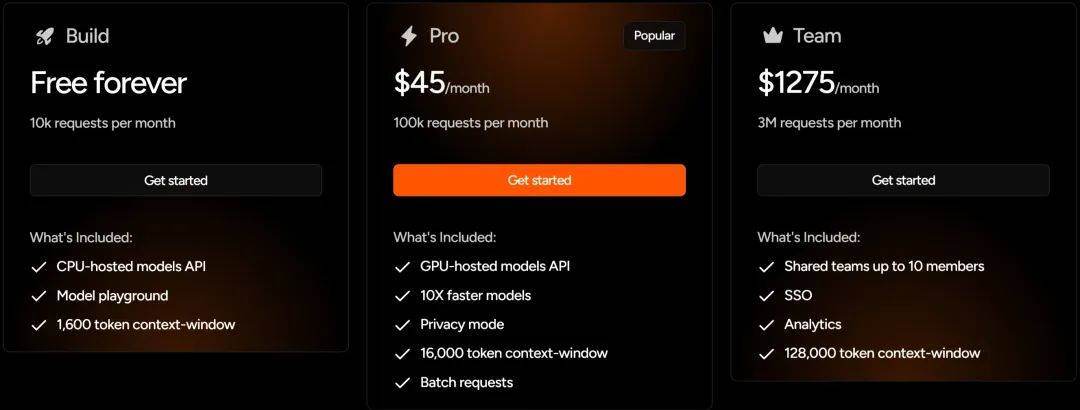
在收费模式上,Fastino采用了订阅制,对初级开发者和中小企业较为友好。个人开发者每月有1万次免费请求,Pro用户每月10万次请求仅需45美元,团队用户300万次请求每月1275美元。Pro用户和团队用户还享有更快模型速度、更安全模型访问及更大上下文窗口等额外优势。
Fastino的TLM模型能够针对开发者和小企业用户提供服务,得益于其极低的模型运行成本。对于企业客户,TLM可部署在客户的虚拟私有云、本地数据中心或边缘设备上,使企业能够在保留敏感信息控制权的同时,利用先进的人工智能能力。
目前,Fastino的TLM已在多个行业产生影响,从金融和医疗领域的文档解析到电子商务中的实时搜索查询智能,财富500强企业正利用这些模型优化运营、提升效率。
在模型规模不断扩大的趋势下,小模型在企业应用中展现出独特优势。低成本、低延迟以及在特定任务上不弱于大尺寸通用模型的优点,使得小模型受到企业和开发者的青睐。这一趋势不仅适用于Fastino,其他模型厂商如Cohere和Mistral也提供强大的小尺寸模型。国内大厂如阿里云的Qwen3也推出了4B、1.7B甚至0.6B的模型。小尺寸模型在成本效益、推理时延和能力匹配上的优势,为它们在AI领域赢得了生存空间。