近期,谷歌DeepMind团队与约翰·开普勒林茨大学的LIT AI实验室携手,在提升语言模型决策能力方面取得了突破。这一成果通过强化学习微调(RLFT)技术实现,旨在解决当前语言模型在决策过程中的一系列问题。
语言模型,经过海量互联网数据的训练,已展现出超越单纯文本处理的潜力。它们能够利用内部知识推理,在交互环境中做出行动选择。然而,这些模型在决策时仍面临诸多挑战。例如,它们能够推导出正确的策略,但在执行时却常常力不从心,形成了所谓的“知道却做不到”的鸿沟。模型还倾向于过度追求短期的高回报,而忽视了长期的利益,这被称为“贪婪选择”。更小的模型则容易陷入机械重复常见动作的困境,即“频次偏见”。
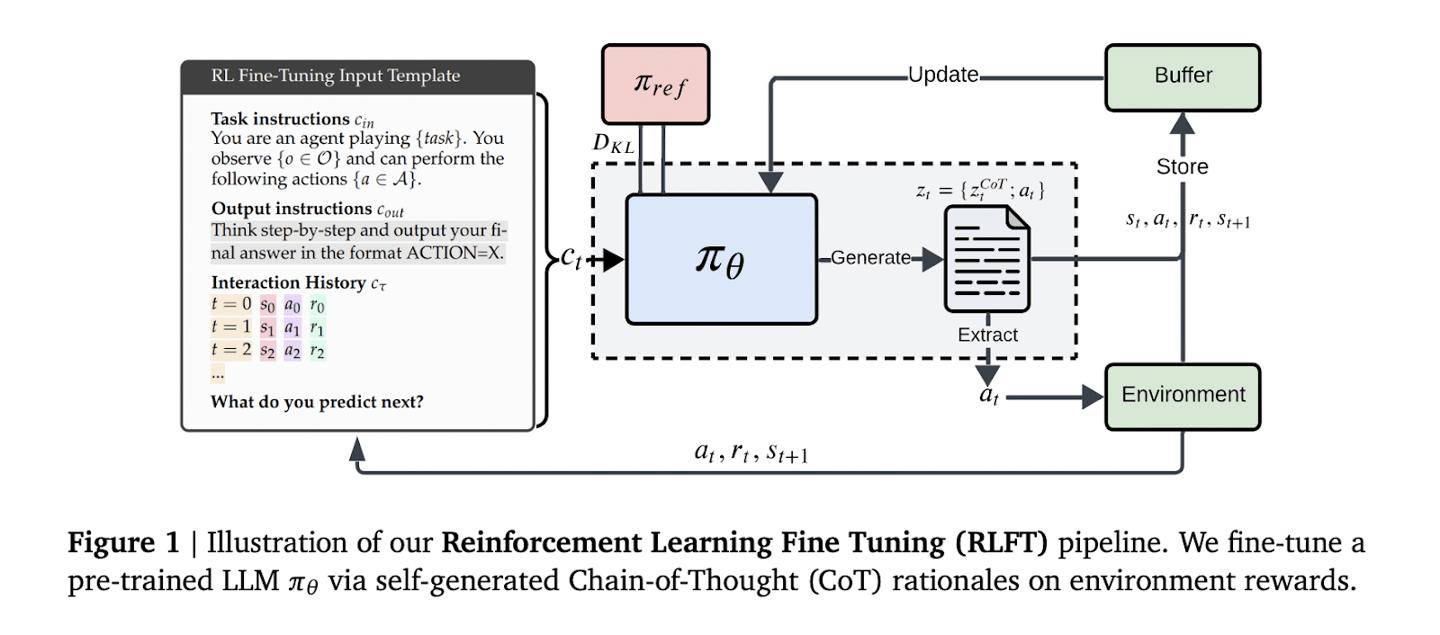
传统强化学习方法,如UCB算法,虽然在平衡探索与利用方面表现出色,但难以从根本上解决语言模型内在的推理与行动脱节问题。为了克服这一难题,DeepMind团队创新性地采用了强化学习微调技术。该技术以模型自生成的思维链为训练信号,通过评估每个推理步骤对应的行动奖励,引导模型优先选择既逻辑自洽又实际高效的行动方案。
在具体实施过程中,模型根据输入的指令和行动-奖励历史,生成包含推理过程和动作的序列。这些序列通过蒙特卡洛基线评估和广义优势估计进行优化。对于无效的动作,系统会触发惩罚机制。同时,奖励塑造技术既确保了输出格式的规范性,又保留了足够的探索空间。
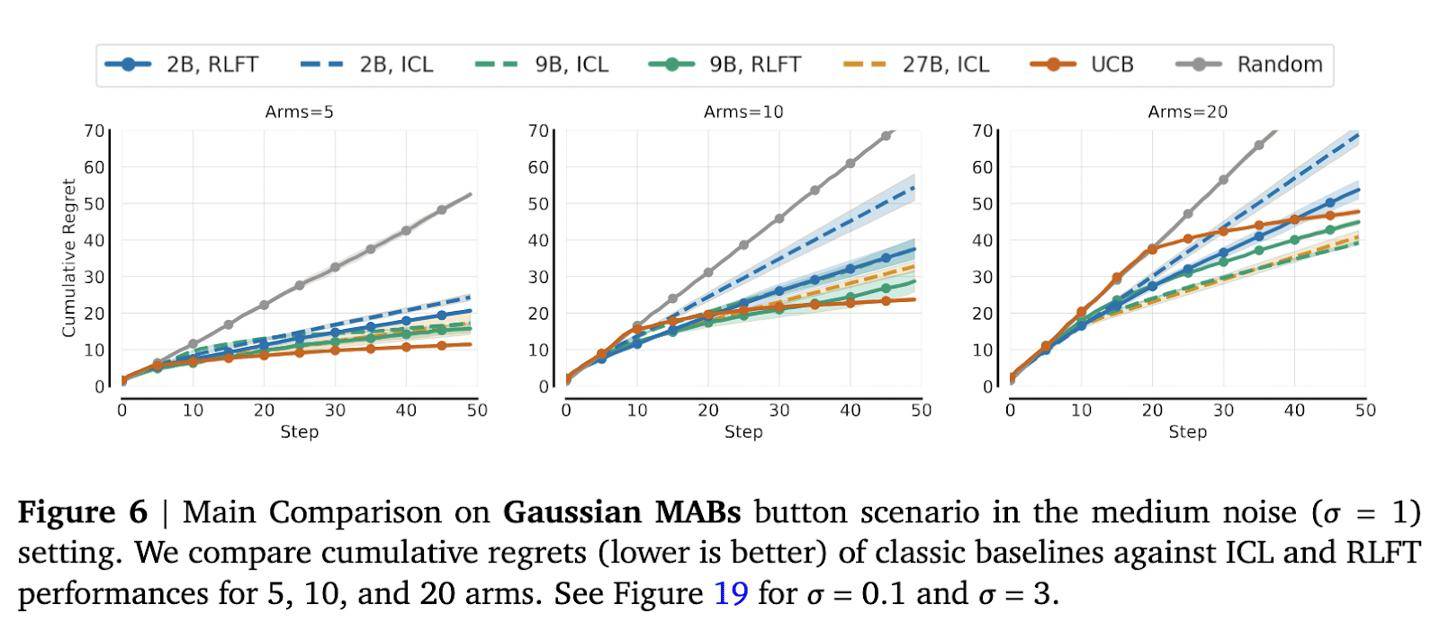
为了验证这一技术的有效性,研究团队进行了多项测试。在多臂老虎机测试中,面对10臂和20臂的情况,模型的动作覆盖率显著提升。特别是在10臂测试中,2B参数模型的动作覆盖率提高了12个百分点。而在20臂测试中,虽然改善幅度较小,但频次偏见率从70%骤降至35%,仍然具有显著意义。
在井字棋实验中,模型的表现同样令人瞩目。与随机对手对战时,模型的胜率提升了5倍。而与最优蒙特卡洛树搜索代理的对战中,模型的平均回报从-0.95归零。值得注意的是,27B大模型在生成正确推理的概率方面达到了87%。然而,在未进行微调时,仅有21%的模型会执行最优动作。这一强化学习微调技术有效地缩小了这一差距,显著提升了模型的决策能力。