近期,科技界传来了一则关于meta公司的最新进展。据marktechpost报道,meta成功推出了J1系列模型,该系列模型在准确性和公平性方面取得了显著突破,这得益于其独特的强化学习和合成数据训练策略。
在大型语言模型(LLM)逐渐承担更多评估与判断任务的大背景下,meta的J1模型应运而生。这种被称为“LLM-as-a-Judge”的模式,使得AI模型能够像法官一样审查其他语言模型的输出,成为强化学习、基准测试和系统对齐的得力助手。J1模型通过内部链式推理(chain-of-thought reasoning)来模拟人类思考过程,特别擅长处理数学解题、伦理推理和用户意图解读等复杂任务,同时支持跨语言和领域的验证,极大地推动了语言模型开发的自动化和扩展性。
然而,“LLM-as-a-Judge”模式也面临着一些挑战,如一致性差、推理深度不足以及位置偏见等问题。传统的评估方法往往依赖基本指标或静态标注,难以有效应对主观或开放性问题。大规模收集人工标注数据不仅成本高昂,而且耗时费力,限制了模型的泛化能力。针对这些问题,meta的GenAI和FAIR团队研发了J1模型,旨在通过创新技术解决现有难题。
J1模型的训练过程采用了强化学习框架,利用可验证的奖励信号进行学习。为了构建数据集,团队精心挑选了22000个合成偏好对,其中包括17000个WildChat语料和5000个数学查询。通过这些数据,训练出了J1-Llama-8B和J1-Llama-70B两款模型。团队还引入了Group Relative Policy Optimization(GRPO)算法,简化了训练流程,并通过位置无关学习(position-agnostic learning)和一致性奖励机制有效消除了位置偏见。
J1模型在判断格式上展现出极高的灵活性和通用性,支持成对判断、评分和单项评分等多种格式。在测试阶段,J1模型表现出色,尤其是在PPE基准测试中,J1-Llama-70B的准确率高达69.6%,超过了DeepSeek-GRM-27B(67.2%)和evalPlanner-Llama-70B(65.6%)。即使是较小的J1-Llama-8B模型,也以62.2%的成绩击败了evalPlanner-Llama-8B(55.5%)。
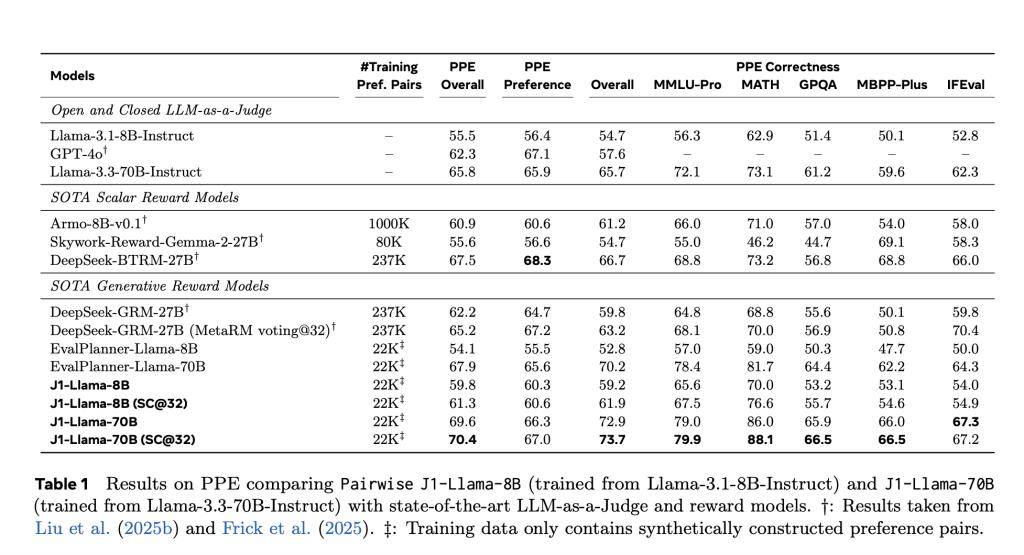
J1模型还在RewardBench、JudgeBench等多个基准测试中表现出色,证明了其在可验证和主观任务上的强大泛化能力。这些测试结果表明,推理质量而非数据量,才是判断模型精准度的关键因素。J1模型的推出,不仅为meta在语言模型领域树立了新的标杆,也为整个AI行业的发展带来了新的启示。
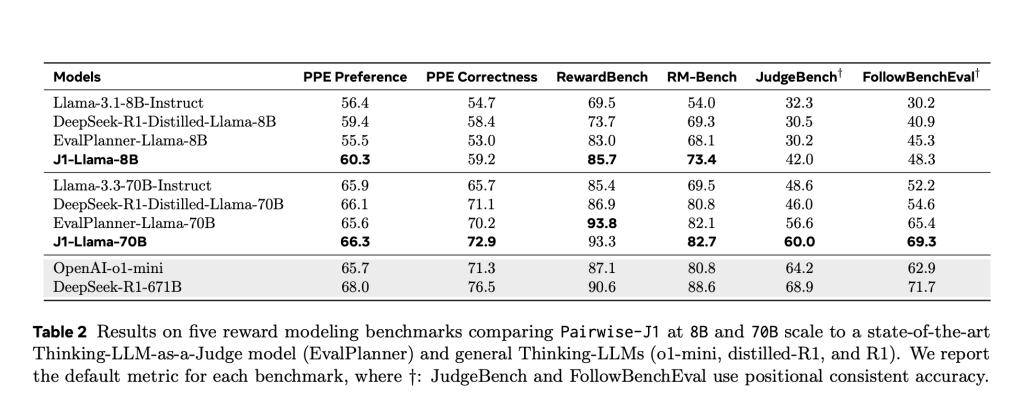
随着J1模型的广泛应用和持续优化,我们有理由相信,未来AI模型在评估与判断任务中将展现出更加卓越的性能和更加广泛的应用前景。这一创新成果不仅推动了meta在AI领域的技术进步,也为全球科技界树立了新的典范。