在科技行业的浩瀚星空中,一系列闪耀的上市公司构成了数字经济的璀璨星河,其中包括阿里巴巴(09988.HK,BABA.US)、百度(09888.HK,BIDU.US)、腾讯(00700.HK, TCEHY)等科技巨头,以及科大讯飞(002230.SZ)、万兴科技(300624.SZ)、三六零(601360.SH)、昆仑万维(300418.SZ)、云从科技(688327.SH)、拓尔思(300229.SZ)等各具特色的创新企业。
近年来,多模态大模型技术成为人工智能领域的热门话题。这类模型通过融合视觉与语言等多种信息模态,实现了更深层次的智能交互。主流方法之一是借助预训练好的大语言模型和图像编码器,通过图文特征对齐模块,让语言模型能够“看懂”图像,进而进行复杂的问答推理。这种方法不仅减少了对高质量图文对数据的依赖,还通过特征对齐和指令微调等技术,实现了不同模态间的无缝衔接。
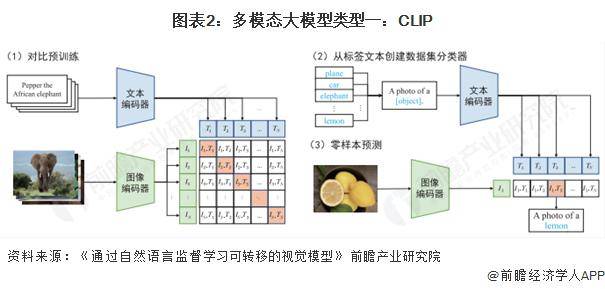
在多模态大模型的探索中,CLIP模型以其独特的对比学习方法脱颖而出。CLIP由OpenAI提出,通过文本信息训练视觉模型,实现了zero-shot分类能力。它利用预训练好的网络,通过计算文本标签与图片的余弦相似度,预测图片的分类结果。CLIP的创新之处在于,它利用句子模板作为提示信息,提高了分类效果,这一方法被称为prompt engineering。

Flamingo模型则是另一款备受瞩目的多模态大型语言模型。它不仅具备CLIP的图像和文本对齐能力,还能根据视觉和文本输入生成文本响应。Flamingo通过视觉编码器将图像转换为嵌入,再与语言模型结合,实现了跨模态的智能交互。其训练数据集包括图像-文本对、视频-文本对以及交错的图像和文本数据集,为模型的泛化能力提供了坚实基础。
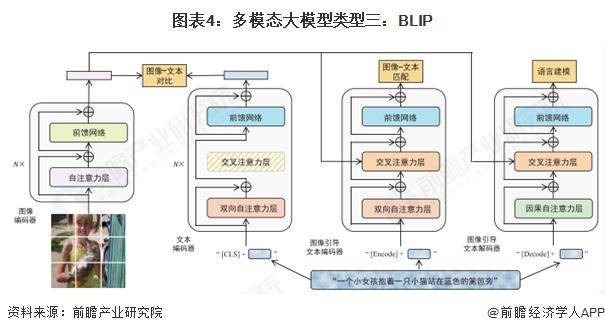
Salesforce提出的BLIP模型,在多模态预训练领域同样占有一席之地。BLIP旨在统一视觉语言任务的理解与生成能力,并通过处理噪声数据来提高模型性能。与CLIP相比,BLIP不仅关注图像和文本的对齐问题,还致力于解决图像生成、视觉问答和图像描述等复杂任务。其采用的引导学习方式,通过自监督手段增强了模型对语言和视觉信息的理解能力。
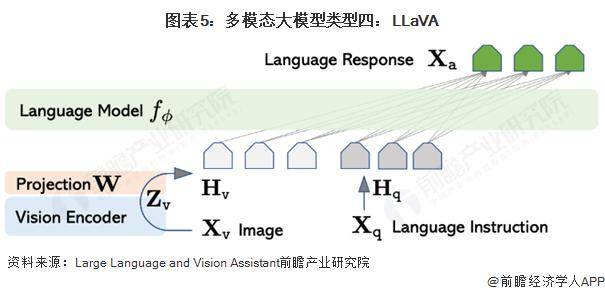
利用视觉编码器CLIP ViT-L/14与语言解码器LLaMA结合,构建多模态大模型,并通过指令微调提升性能,也是当前研究的一大热点。这种方法通过将视觉Token与语言Token置于同一特征空间,实现了跨模态的信息融合与交互,为人工智能的未来发展开辟了新的道路。


