英伟达近日宣布了一项令人瞩目的成就:其最新推出的Blackwell GPU在meta的Llama 4 Maverick模型上,成功刷新了大型语言模型(LLM)推理速度的世界纪录。这一突破发生在周四,当时英伟达正式对外公布了这一消息。
据悉,为了达到这一里程碑,AI基准测试权威机构Artificial Analysis采用了配置了8块Blackwell GPU的DGX B200节点。这一配置使得系统每用户每秒能够生成高达1000个tokens(TPS),这在之前是难以想象的。

英伟达的技术团队通过深度优化TensorRT-LLM软件栈,并结合EAGLE-3技术,对推测解码草稿模型进行了训练。这种加速技术通过小型快速草稿模型预测token序列,再由大型目标LLM进行并行验证。英伟达表示,这种方法的优势在于单次迭代可能生成多个token,尽管这需要额外的草稿模型计算开销。经过这些优化,整套服务器系统在峰值吞吐配置下,每秒能够处理72,000个tokens。
英伟达进一步解释说,Blackwell架构与Llama 4 Maverick级别的超大规模语言模型完美适配,这得益于其专为大型语言模型推理加速设计的EAGLE3软件架构。这一架构与GPU硬件架构形成了协同效应,从而实现了性能的显著提升。
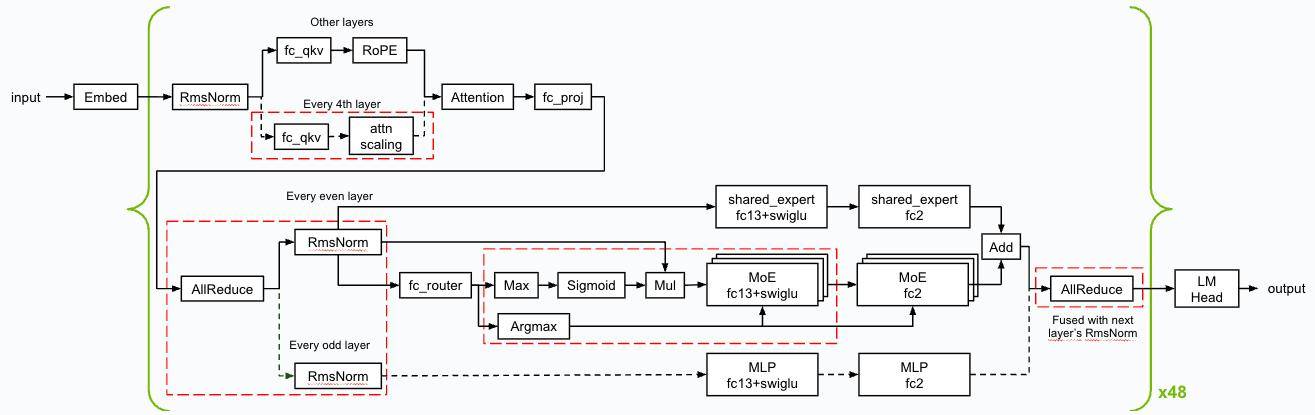
英伟达还强调,他们在提高性能的同时,也确保了响应的准确性。测试结果显示,使用FP8数据格式的准确性与人工分析的BF16数据格式相当。这意味着,在保持高准确性的前提下,英伟达成功地大幅提高了系统的性能。

英伟达的这一突破,不仅展示了其在GPU技术领域的领先地位,也为大型语言模型的推理加速提供了新的解决方案。随着人工智能技术的不断发展,这一突破将对未来的AI应用产生深远的影响。