近日,备受瞩目的SuperCLUE发布了其最新的《中文大模型基准测评报告》,该报告针对2025年5月的中文大模型能力进行了全面评估。
在本次测评中,有两款模型尤为突出,它们分别是豆包1.5深度思考模型(Doubao-1.5-thinking-pro)和商汤科技的日日新V6多模态模型(SenseNova-V6 Reasoner)。这两款模型凭借其卓越的表现,成功超越了之前的领先者Gemini 2.5 Flash Preview,成为当前中文大模型领域的佼佼者。
紧随其后的第二梯队模型同样不容小觑,包括DeepSeek-R1、NebulaCoder-V6、Hunyuan-T1和DeepSeek-V3。这些模型在各自的领域内均有着出色的表现,并在本次测评中展现出了强大的竞争力。
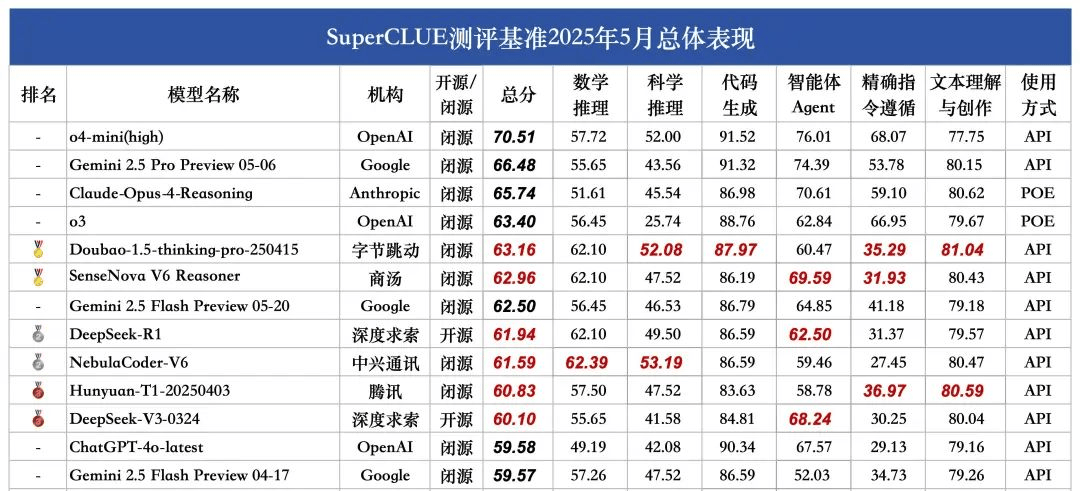
据SuperCLUE报告指出,当前国内外中文大模型在通用能力方面的差距正在逐渐缩小。在国内市场中,Doubao-1.5-thinking-pro-205415和SenseNova V6 Reasoner凭借其出色的表现,成功吸引了业界的广泛关注。这两款模型的出色表现,也预示着国内推理模型市场的竞争格局正在逐步形成。
SuperCLUE作为行业权威的通用大模型综合性测评基准,其本次测评覆盖了数学推理、科学推理、代码生成、智能体Agent、精确指令遵循以及文本理解与创作六大任务。测评题目总量达到了1579道多轮简答题,旨在全面评估大模型在中文环境下的通用能力。
通过本次测评,我们可以清晰地看到当前中文大模型领域的竞争格局以及各模型的优劣所在。这不仅为行业内的研发者提供了宝贵的参考信息,也为广大用户提供了更加准确的选择依据。







