近日,备受瞩目的SuperCLUE发布了其最新的《中文大模型基准测评报告》,该报告详细阐述了2025年5月份中文大模型的最新表现。
在此次测评中,豆包1.5·深度思考模型(Doubao-1.5-thinking-pro)与商汤日日新V6多模态模型(SenseNova-V6 Reasoner)脱颖而出,成功夺得金牌,将Gemini 2.5 Flash Preview甩在身后,领跑国内大模型的第一梯队。
紧随其后的是第二梯队的大模型们,包括DeepSeek-R1、NebulaCoder-V6、Hunyuan-T1和DeepSeek-V3,它们虽然在本次测评中未能摘得金牌,但同样展现出了不俗的实力。
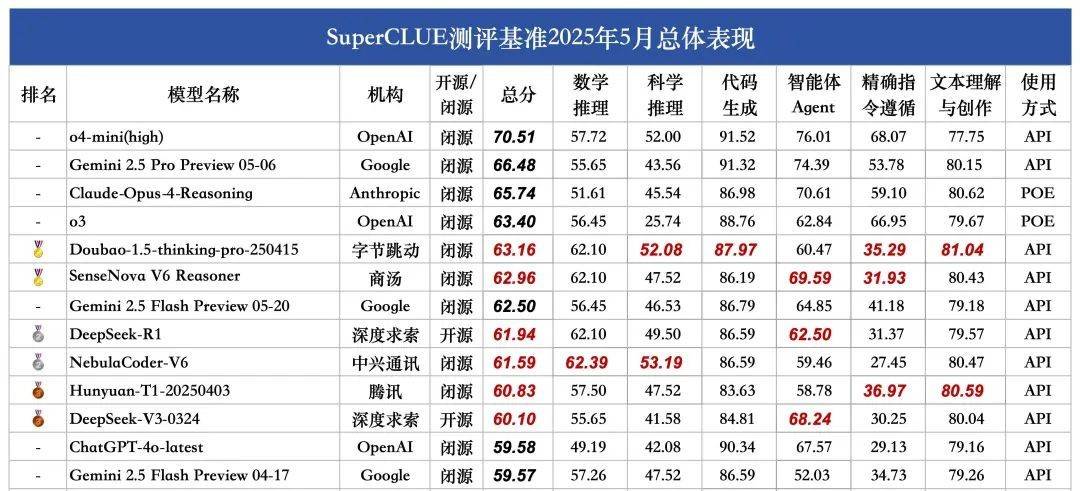
据报告分析,国内外第一梯队大模型在中文领域的通用能力差距正在逐渐缩小,这对于国产大模型来说无疑是一个好消息。其中,Doubao-1.5-thinking-pro-205415和SenseNova V6 Reasoner的表现尤为抢眼,它们在多个测评任务中都展现出了卓越的能力。
本次SuperCLUE的测评报告聚焦大模型的通用能力,涵盖了数学推理、科学推理、代码生成、智能体Agent、精确指令遵循以及文本理解与创作六大任务,总计1579道多轮简答题。这些任务全面考察了大模型在不同场景下的应用能力和表现。
SuperCLUE作为行业权威的通用大模型综合性测评基准,其发布的报告一直备受关注。此次报告的发布,不仅揭示了当前中文大模型的最新发展态势,也为未来大模型的研究和应用提供了重要的参考依据。







