阿里巴巴旗下的通义团队近日宣布了一项重大进展,正式推出了基于千问3大模型的全新向量模型系列——Qwen3-Embedding。这一系列的发布,标志着千问3在文本表征、检索及排序等核心任务上的又一次飞跃,性能相较于其前代模型有了显著提升,最高可达40%。
Qwen3-Embedding系列模型,作为千问3的衍生产品,其设计初衷便是为了优化和提升AI在文本处理方面的能力。通过先进的对比训练、SFT技术以及模型融合策略,通义团队成功地打造出了这一系列的文本嵌入模型Qwen3-Embedding和文本排序模型Qwen3-Reranker。
向量模型,被誉为AI的“翻译官”,它们能够将人类所能理解的非结构化信息,如文本和图片,转化为机器更易处理的向量形式。这一转化过程为AI在信息分类、检索及排序等方面提供了强有力的支持,极大地提升了AI的语义理解和信息处理能力。Qwen3-Embedding系列模型的推出,正是基于这一理念,旨在进一步提升AI在这些方面的性能。
在权威的多语言向量评估榜单MTEB上,Qwen3-Embedding-8B模型凭借其卓越的性能,成功超越了谷歌的Gemini Embedding、OpenAI的text-embedding-3-large以及微软的multilingual-e5-large-instruct等顶尖模型,夺得了同类模型的最佳性能SOTA。这一成就不仅彰显了Qwen3-Embedding系列模型的强大实力,也体现了阿里巴巴在AI技术领域的深厚底蕴。
Qwen3向量模型系列还具备出色的多语言能力。得益于千问3大模型的多语言特性,Qwen3-Embedding系列模型支持超过100种语言,并涵盖了多种编程语言。这一特性使得Qwen3向量模型系列在跨语言检索、代码检索等方面展现出了强大的能力。
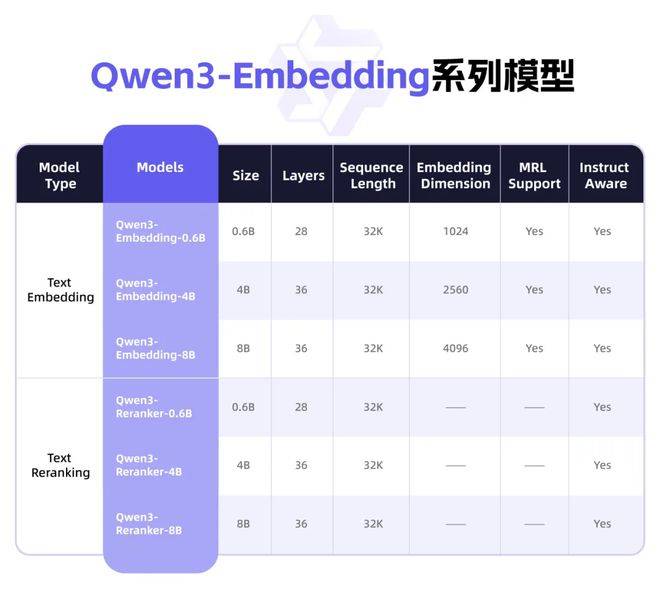
为了方便开发者更好地利用Qwen3向量模型系列,阿里巴巴此次开源了9款不同尺寸和版本的模型,包括0.6B、4B、8B等。开发者可以根据自己的需求选择合适的模型,自由组合模块,并自定义向量或指令,以实现特定任务、语言和场景的深度优化。例如,在智能搜索和推荐系统中,开发者可以采用Qwen3-Embedding模型进行文本向量化;在RAG实践中,可以利用Qwen3-Reranker模型提升最终结果的相关性和准确性;甚至还可以与视觉理解模型结合,探索前沿的跨模态语义理解。
目前,Qwen3 Embedding和Reranker模型已经在魔搭社区、Hugging Face和GitHub等平台上开源,开发者可以直接通过阿里云百炼使用API服务。这一举措无疑将为AI技术的普及和发展提供有力的支持。
自4月29日千问3大模型开源以来,它已经在国内外的多个权威榜单上取得了优异的成绩,包括Artificial Analysis、LiveBench、LiveCodeBench和SuperClue等。这些成绩的取得,不仅证明了千问3大模型的强大实力,也展示了阿里巴巴在AI技术领域的持续创新和突破。







