近日,一款名为Kimi-Dev-72B的全新开源代码大模型震撼发布,由神秘团队月之暗面在凌晨悄然推出,专为软件工程任务设计。
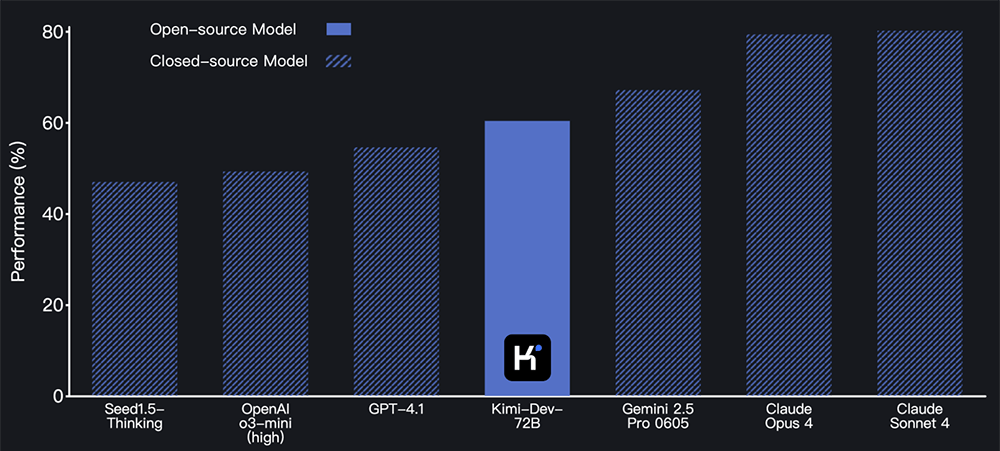
这款模型在业界权威的SWE-bench Verified编程基准测试中大放异彩,以仅720亿参数的规模,力压群雄,成绩超越了不久前发布的、参数高达6710亿的新版DeepSeek-R1,树立了开源模型的新标杆。

在SWE-bench Verified测试中,Kimi-Dev-72B取得了高达60.4%的惊人分数,这一成绩不仅彰显了其卓越的软件工程能力,也标志着开源模型在AI辅助编程领域迈出了重要一步。
Kimi-Dev-72B的成功并非偶然。其背后是月之暗面团队通过大规模强化学习进行的精心优化。该模型能够自主修补Docker中的真实存储库,并且只有当整个测试套件通过时才会获得奖励,从而确保了解决方案的正确性和稳健性,符合现实世界的开发标准。
目前,Kimi-Dev-72B已在Hugging Face和GitHub上开放下载和部署。用户不仅可以获取模型权重和源代码,技术报告也将随后推出,为社区提供了宝贵的研究资源。
Kimi-Dev-72B的设计理念和技术细节同样令人瞩目。月之暗面团队巧妙地将BugFixer和TestWriter相结合,形成了独特的双重设计。这一设计使得模型在修复代码错误和编写单元测试方面都能表现出色。同时,通过中期训练和强化学习,Kimi-Dev-72B进一步增强了其编程能力。
在中期训练阶段,月之暗面团队使用了约1500亿个高质量的真实数据,以Qwen 2.5-72B基础模型为起点,精心构建了数据配方,使Kimi-Dev-72B能够学习人类开发者如何推理GitHub问题、编写代码修复和单元测试。这一阶段的训练为后续的强化学习打下了坚实的基础。
而在强化学习阶段,Kimi-Dev-72B则专注于提升其代码编辑能力。月之暗面团队采用了高效的策略优化方法,并重点关注了仅基于结果的奖励、高效的提示集以及正例强化等关键设计。这些设计使得模型在训练过程中能够更有效地利用资源,提升性能。
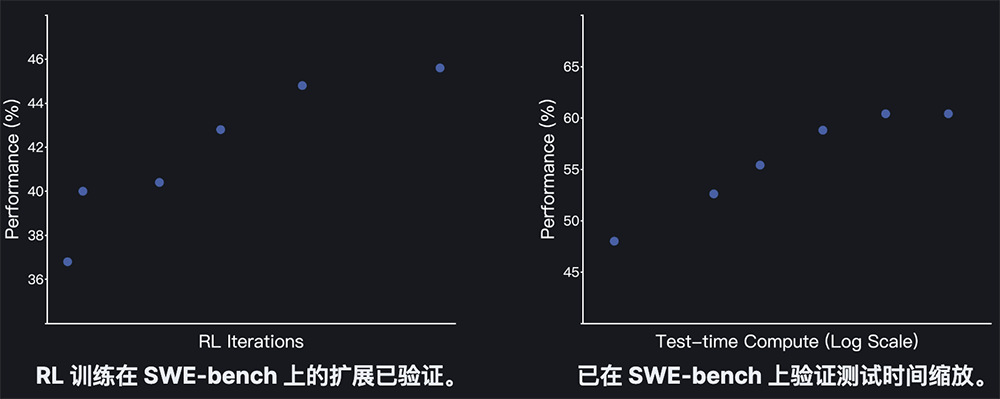
Kimi-Dev-72B在测试过程中还采用了自我博弈机制。这一机制使得模型能够协调自身Bug修复和测试编写的能力,进一步提升了其整体性能。