| 公众号 QbitAI
这两天啊,各地高考的成绩终于是陆续公布了。
现在,也是时候揭晓全球第一梯队的大模型们的“高考成绩”了——
我们先来看下整体的情况(该测试由字节跳动Seed团队官方发布):
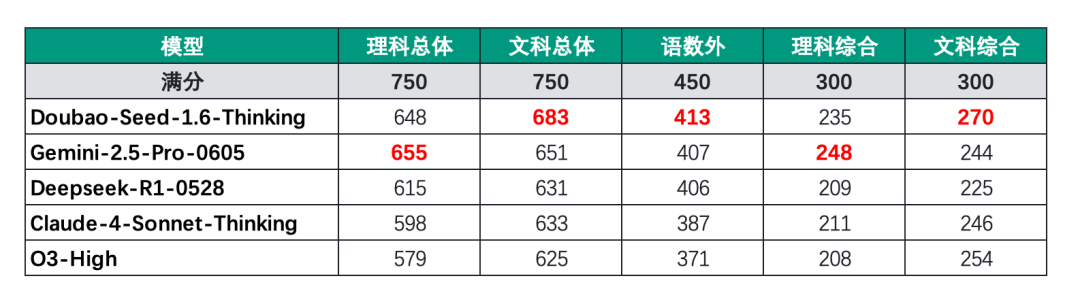
按照传统文理分科计分方式,Gemini的理科总成绩655分,在所有选手里排名第一。豆包的文科总成绩683分,排名第一,理科总成绩是648分,排名第二。
再来看下各个细分科目的成绩情况:
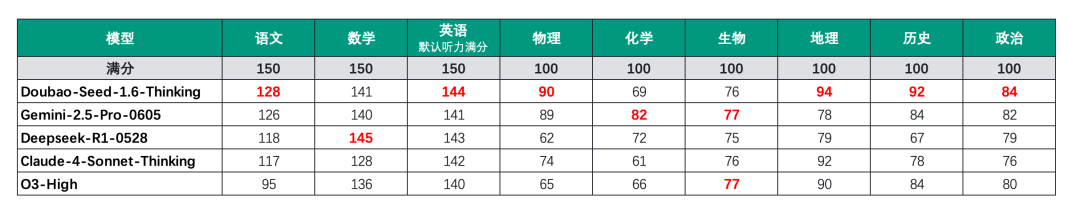
除了数学、化学和生物之外,豆包的成绩依旧是名列前茅,6个科目均是第一。
不过其它AI选手的表现也是比较不错,可以说是达到了优秀学生的水准。
比较遗憾的选手就要属O3,因为它在语文写作上跑了题,因此语文成绩仅95分,拉低了整体的分数。
若是从填报志愿角度来看,因为这套测试采用的是山东省的试卷,根据过往经验判断,3门自选科目的赋分相比原始分会有一定程度的提高,尤其是在化学、物理等难度较大的科目上。本次除化学成绩相对稍低外,豆包的其余科目组合的赋分成绩最高能超过690分,有望冲刺清华、北大。
进一步强化文本数据的知识与推理密度,增加学科、代码、推理类数据占比,同时引入视觉模态数据,与高质量文本混合训练。
第三阶段:长上下文持续训练(LongCT)
通过不同长度的长文数据逐步扩展模型序列长度,将最大支持长度从32K提升至256K。
通过模型架构、训练算法及Infra的持续优化,Seed1.6 base模型在参数量规模接近的情况下,性能较Seed1.5 base实现显著提升,为后续后训练工作奠定基础。
这一招的发力,就对诸如高考语文阅读理解、英语完形填空和理科综合应用题等的作答上起到了提高准确率的作用,因为它们往往涉及长文本且看重上下文理解。
第二招:多模态融合的深度思考能力
Seed1.6-Thinking 延续Seed1.5-Thinking的多阶段RFT(强化反馈训练)与RL(强化学习)迭代优化方法,每轮RL以上一轮RFT为起点,通过多维度奖励模型筛选最优回答。相较于前代,其升级点包括:
拓展训练算力,扩大高质量数据规模(涵盖 Math、Code、Puzzle 等领域);
提升复杂问题的思考长度,深度融合VLM能力,赋予模型清晰的视觉理解能力;
引入parallel decoding技术,无需额外训练即可扩展模型能力 —— 例如在高难度测试集Beyond AIME中,推理成绩提升8分,代码任务表现也显著优化。
这种能力直接对应高考中涉及图表、公式的题目,如数学几何证明、物理电路图分析、地理等高线判读等;可以快速定位关键参数并推导出解题路径,避免因单一模态信息缺失导致的误判。
第三招:AutoCoT解决过度思考问题
深度思考依赖Long CoT(长思维链)增强推理能力,但易导致 “过度思考”—— 生成大量无效token,增加推理负担。
为此,Seed1.6-AutoCoT提出 “动态思考能力”,提供全思考、不思考、自适应思考三种模式,并通过RL训练中引入新奖励函数(惩罚过度思考、奖励恰当思考),实现CoT长度的动态压缩。
在实际测试中:
中等难度任务(如 MMLU、MMLU pro)中,CoT 触发率与任务难度正相关(MMLU 触发率37%,MMLU pro触发率70%);
复杂任务(如AIME)中,CoT触发率达100%,效果与Seed1.6-FullCoT相当,验证了自适应思考对Long CoT推理优势的保留。
以上就是豆包能够在今年高考全科目评测中脱颖而出的原因了。
不过除此之外,还有一些影响因素值得说道说道。
正如我们刚才提到的,化学和生物的题目中读图题占比较大,但因非官方发布的图片清晰度不足,会导致多数大模型的表现不佳;不过Gemini2.5-Pro-0605的多模态能力较突出,尤其在化学领域。
不过最近,字节Seed团队在使用了更清晰的高考真题图片后,以图文结合的方式重新测试了对图片理解要求较高的生物和化学科目,结果显示Seed1.6-Thinking的总分提升了近30分(理科总分达676)。
 图文交织输入示例
图文交织输入示例
这说明,全模态推理(结合文本与图像)能显著释放模型潜力,是未来值得深入探索的方向。
那么你对于这次大模型们的battle结果有何看法?欢迎大家拿真题去实测后,在评论区留言你的感受。