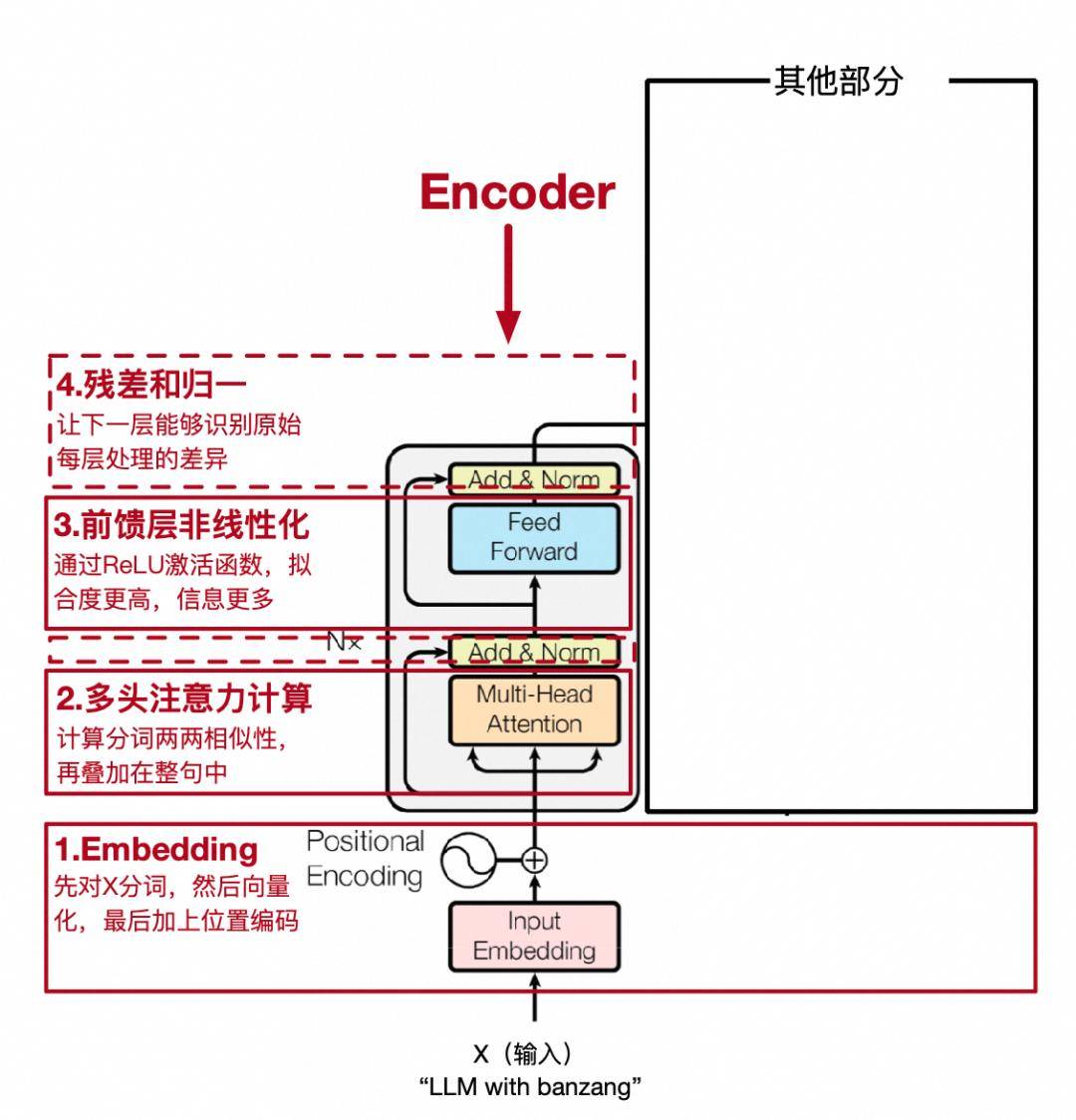
在深度学习领域,模型训练过程中的性能优化一直是一个备受关注的话题。特别是在处理复杂任务如自然语言理解时,模型的每一层网络都会增加计算负担,可能导致梯度下降过程中的不稳定现象。梯度在下降过程中,有时会跳过最优解,或在最优解附近徘徊,这不仅消耗了大量计算资源,还可能影响模型的最终性能。
为了解决这一问题,研究者们不断探索新的网络架构。2015年,微软亚洲研究院提出的ResNet架构,在卷积神经网络中引入了“跳跃连接”的概念,为Transformer模型提供了灵感。这种连接允许梯度直接反向传播到更原始的层,从而有效缓解了网络深度带来的“退化”问题。在Transformer中,输入X不仅被传递给每一层进行处理,还通过跳跃连接直接与该层的输出Y相加。这种设计使得后续层能够学习到当前层处理与原始输入之间的差异,而非仅仅依赖于上一层的处理结果。这种机制允许网络学习到恒等映射,即输出与输入相同,为模型提供了更简单的路径来学习正确的映射关系。
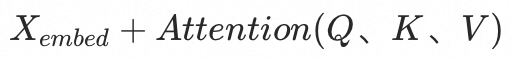
在实现跳跃连接时,由于X和Y的维度相同,因此可以直接相加。然而,为了确保相加操作的有效性,通常需要对每一层的输出进行归一化处理。这一过程包括计算矩阵每行的均值和方差,然后用每行的元素减去均值并除以标准差(为了避免除以零的情况,通常会加上一个小的常数)。最后,通过引入可训练的参数a和b,来抵消归一化过程中可能引入的损失。
经过跳跃连接和归一化处理后,Transformer模型的第一阶段处理基本完成。为了增加模型的非线性表达能力,通常会再添加一个非线性层,即一个简单的全连接神经网络。这一层通过权重矩阵和偏置项对输入进行线性变换,并引入非线性激活函数,从而使模型能够学习到更丰富的特征表示。之后,模型还会再次进行归一化处理,以确保输出的稳定性。
Transformer模型的这一阶段被封装为一个独立的模块,称为编码器(Encoder)。编码器能够捕捉句子中每个词与整个句子的关联性,使得每个词向量都包含了句子中所有词的信息以及它们之间的关联度。这一特性使得Transformer模型在自然语言处理任务中表现出色,尤其是在机器翻译、文本生成等领域。