步入2025年的中点,大模型技术的飞速发展令人瞩目,尤其以年初DeepSeek的火爆为引爆点,大模型不再局限于实验室,而是大步流星地融入企业的核心业务系统,政务、金融、医疗、能源等多个领域纷纷见证了其加速落地的身影。
随着大模型深入实际应用,CTO们的关注点开始从基础模型转向推理引擎,推理过程中的资源利用效率——每一度电、每一块钱、每一分钟所能产出的Token数量,已成为衡量企业在AI时代竞争力的关键标尺。如何借助推理引擎提升推理效率、最大化算力价值、尽可能削减推理成本,成为了CTO们亟待解决的重大课题。
大模型在实际应用中面临的一大挑战,便是推理引擎的性能瓶颈。推理引擎,简而言之,是一套确保大模型高效运行的系统,它不仅负责计算方式,还决定了计算地点和计算速度,旨在最大化提升大模型推理的响应速度、并发能力和算力资源利用率。如果将大模型比作发动机,推理引擎则是动力总成,决定了发动机在各种条件下的运行效率。调校得当,则能实现低延迟、高吞吐、低成本;调校不当,即便是强大的模型也可能出现“高耗低效”的问题。
自2023年起,推理引擎作为独立赛道逐渐兴起,涌现了诸如TGI、vLLM、TensorRT、SGLang等面向推理效率优化的开源项目。然而,当时业界主要聚焦于模型训练,对推理引擎的需求尚不迫切。2025年初,以DeepSeek等为代表的大模型开源后,企业对AI的态度由观望转为积极行动,但在落地部署时却遭遇了推理响应慢、吞吐不足、成本高昂等难题。高达90%的算力消耗在推理环节,却难以获得理想的性价比。
大模型推理的难题在于效果、性能、成本之间的“不可能三角”。追求更好的效果,意味着需要更大的模型、更高的精度、更长的上下文,但这会显著增加算力开销;追求更快的运行速度,可能需要使用缓存、批处理、图优化等技术,但这可能会影响模型输出的质量;追求更低的成本,则可能需要压缩模型、降低显存、使用更经济的算力,但这可能会牺牲推理的性能或准确率。
面对这些挑战,推理引擎赛道逐渐热闹起来。不少在AI应用上先行一步的大厂,也意识到了推理引擎的短板,试图将自身摸索出的经验转化为标准化产品和服务,帮助企业减轻应用负担。例如,英伟达推出了推理框架Dynamo,AWS的SageMaker提供了多项增强功能以提高大模型推理的吞吐量、降低延迟并提高可用性,京东云推出了JoyBuilder推理引擎,可将推理成本降低90%。
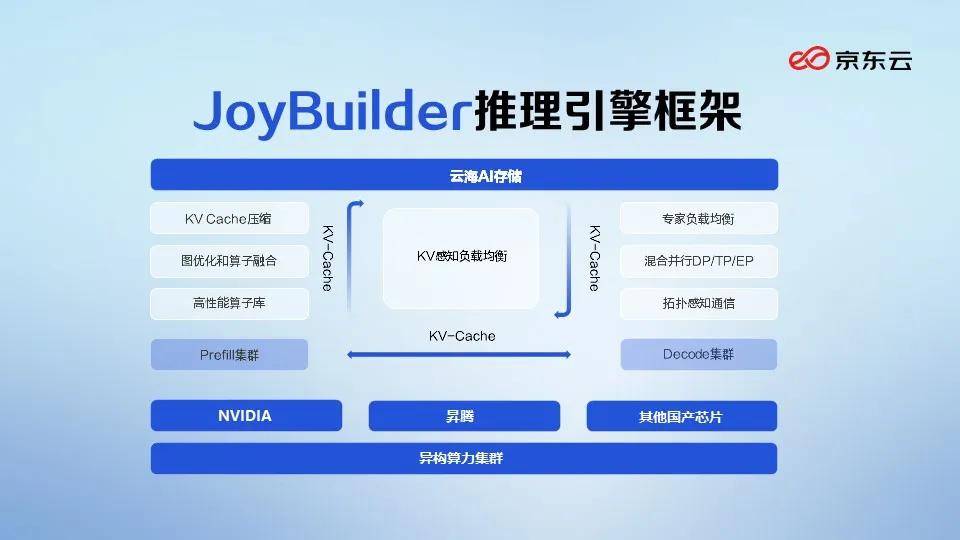
为了提高推理能力,过去主要聚焦于模型优化,通过剪枝、蒸馏、量化等技术给大模型“瘦身”。然而,越来越多的企业发现,单纯的模型优化难以显著提升推理效能,必须优化推理流程。大模型的推理过程可以拆解为两个阶段:第一阶段是“预填充”(Prefill),即理解输入内容;第二阶段是“解码”(Decode),即生成输出内容。AWS、京东云、英伟达、谷歌云等企业,都在工程创新方面投入了大量精力。
例如,AWS SageMaker和谷歌云Vertex AI通过优化“思考地图”(即KVCache),建立了缓存共享中心,动态调度显存资源,提高了GPU的利用率。京东云JoyBuilder推理引擎和英伟达的Dynamo则采用了“以存代算”的解决方案,将“思考地图”从GPU中移出,通过自研的云海AI存储,支持PB级缓存扩展,大幅降低了多轮对话和长文本处理的响应时延。
这些企业还在探索将“听”(理解输入)和“说”(生成输出)分离,以提高推理吞吐量。AWS不仅实现了“听”和“说”的分离,还改变了大模型的输出方式,通过提前整理大纲,减少了思考时间。京东云JoyBuilder推理引擎则采用了不同的方案:一方面与AWS类似,提升了整体吞吐;另一方面,将“听”和“说”的任务分配给不同的GPU处理,实现了并行工作,显著提高了推理吞吐量。
在异构算力方面,随着大模型应用的深入,以CPU为中心的架构在支持AI原生应用上面临挑战,需要以GPU为中心重塑基础设施。然而,异构算力,即将不同品牌的芯片混合使用,带来了新的问题。不同品牌的芯片指令集、运算逻辑都不统一,给管理和调度带来了巨大挑战。目前,vLLM、SGLang等开源引擎在异构集群的调度方面仍显不足,但国内的研究机构和科技大厂正在积极寻求解决方案。
一种主流思路是将异构算力资源统一管理,按需分配给多个模型和任务。例如,京东云JoyBuilder推理引擎可以将一张GPU切成多个小份,显存也能按MB级别分配,从而提高了GPU的利用率。另一种思路是将不同芯片的优势与模型的不同部分相结合,例如在MoE模型的部署上,可以将不同专家部署在不同GPU上,充分利用不同算力的优势。

大模型已经成为新的增长引擎,在营销推广、协同办公、客户服务等场景中深度应用。例如,在零售场景,AI生成商品图、AI营销内容生成、AI数字人等技术正在改变用户的购物体验。京东云JoyBuilder推理引擎源于京东自身复杂业务场景的打磨,基于企业级的AI Native架构,正在广泛服务于内外部众多业务场景。据京东透露,推理框架已经在内部多个场景应用,显著提升了响应速度,节省了计算成本,同时助力了用户活跃度的提升。
除了服务于京东内部,京东云推理引擎也广泛服务于外部产业客户,提供高性能、低成本的大模型服务。在某新能源汽车头部厂商和某全球新能源科技领导企业的实践中,京东云成功打造了覆盖全集团的智能计算底座,实现了千卡级AI算力集群的精细化管理。通过创新多元算力调度和创建全生命周期AI开发环境,显著提升了GPU利用率和研发效率,成为集团的“数智发动机”。预计一年内,这两家企业的大模型训练周期将缩短40%,每年节省的算力成本相当于新建两座数据中心。