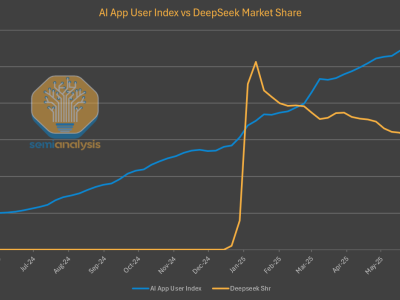
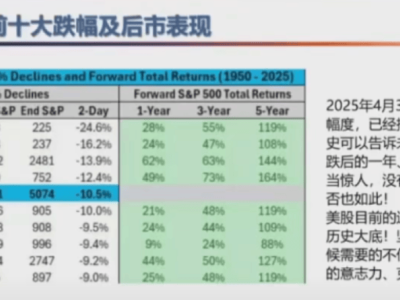
在AI领域的探索之旅中,一场关于大模型架构的新革命正悄然酝酿。近日,一份深度报告揭示了这一领域的最新动向,探讨了谁将成为下一代架构的领军者。
自Transformer架构横空出世以来,AI界对其路径依赖的争议便不绝于耳。面对这一现状,行业对架构创新的渴求愈发迫切。目前,业界主要有两大探索方向:一是对Transformer进行改良,通过稀疏Attention等技术,提升计算效率和内存利用率;二是开辟非Transformer架构的新天地,摆脱对Attention机制的依赖,在长序列建模等方面展现独特优势,且这些创新架构往往呈现出融合的特点。
回顾大模型架构的发展历程,从深度学习初入NLP领域,到Transformer时代的开启,预训练与Scaling Law范式主导一切,再到Transformer时代达到巅峰,基础模型参数规模屡创新高,每一步都见证了AI的飞速进步。然而,时至今日,预训练范式已渐显疲态,创新架构的探索热潮正在兴起。
Transformer架构虽强,但并非无懈可击。其二次计算复杂度导致的算力消耗大、端侧部署局限性大、长序列任务效率低等问题,成为了制约其进一步发展的瓶颈。因此,业界开始围绕Transformer的Attention机制、FFN层等进行改进,同时也在积极探索非Transformer架构的新路径,如新型RNN、新型CNN等,每条路径都有其独特的代表工作和核心思想。
在架构创新的道路上,行业内部存在着不同的声音。一方面,有人认为突破智能天花板是当务之急;另一方面,也有人主张通过压缩智能密度来寻求突破。这两种观点虽然看似对立,但实际上却推动了混合架构逐渐成为趋势。架构创新也遵循着技术迭代周期律,目前正处于新技术突破的前夜。

报告中展示了多种创新架构的对比图,清晰呈现了不同架构之间的优势和劣势。这些图表不仅为研究人员提供了直观的参考,也预示着AI架构领域即将迎来一场深刻的变革。

在这场变革中,谁将成为新的王者尚不得而知。但可以肯定的是,随着技术的不断进步和创新探索的不断深入,AI领域必将迎来更加广阔的发展空间和更加美好的未来。