近期,一项针对大型语言模型(LLM)的研究揭示了一个惊人的发现:当输入文本的长度扩展到1万个tokens时,多个主流大模型的性能出现了显著下滑,宛如“智商”骤降。这一现象并非均匀发生,而是在某些特定节点上,模型的准确率出现了断崖式下跌。
以Claude Sonnet 4为例,在处理1000个tokens后,其准确率从90%一路下滑至60%。而GPT-4.1和Gemini 2.5 Flash则表现出先下降后放缓再下降的趋势。当上下文长度达到1万个tokens时,这些模型的准确率普遍降至50%左右。

这意味着,大模型在阅读同一本书的不同页面时,其“智商”可能会截然不同。更令人惊讶的是,不同大模型在“阅读这本书”的过程中,出现性能骤降的页面也各不相同。例如,GPT-4.1可能在读到第10页时就已“失智”,而Claude或许能坚持到第100页。
这项研究由Chroma团队完成,他们利用升级版的“大海捞针”(NIAH)测试方法,对包括GPT-4.1、Claude 4、Gemini 2.5和Qwen3等在内的18个主流大模型进行了测试。测试结果显示,随着输入长度的增加,模型的性能呈现出越来越差的趋势。
研究还首次系统性地揭示了输入长度对模型性能的非均匀影响。实验表明,不同模型的性能可能在某一特定的tokens长度上,准确率发生骤降。这一发现得到了网友的广泛认可,因为以往人们虽然遇到过输入长度增加时大模型性能不佳的情况,但并未有人深入探究过这个问题。
为了更深入地了解输入长度对模型性能的影响,研究人员设计了四项对照实验。这些实验基于保持任务复杂度不变,仅改变输入长度的核心原则,旨在探究语义关联性、干扰信息、文本结构等因素对模型性能的影响。
实验结果显示,输入长度是性能衰减的核心变量。无论任务简单与否,模型在处理长文本时的可靠性都会下降。语义关联性、干扰信息和文本结构等因素会进一步加剧模型的性能衰减。例如,在针-问题相似度实验中,低相似度组的模型性能衰减更为显著;在干扰信息实验中,即使单一干扰项也会导致模型性能低于基线,而多重干扰项会进一步加剧性能衰减。
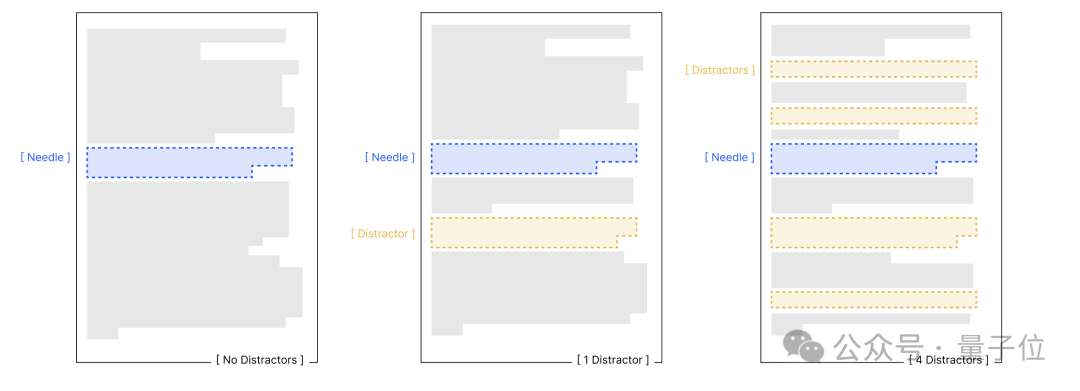
不同模型对这些因素的敏感程度也存在差异。例如,Claude系列模型在不确定时倾向于弃权,表现出较低的幻觉率;而GPT系列模型则更可能生成自信但错误的答案,受干扰影响更明显。Gemini和Qwen模型的表现则波动较大,易受干扰项数量和输入长度的双重影响。
这项研究不仅揭示了大型语言模型在处理长文本时的局限性,也为未来的研究提供了新的方向。研究人员建议,在构建LLM应用时,应给出明确、清晰的指令,并在收集到足够的信息后保存上下文,以添加一个检查点来提高模型的稳定性和可靠性。
Chroma团队不仅致力于LLM长上下文处理领域的研究,还开发了一个开源的AI应用数据库——Chroma。该数据库旨在通过将知识和技能整合为大语言模型可调用的模块,简化LLM应用的构建过程。目前,Chroma计划推出免费的技术预览,并表示将100%专注于构建有价值的开源软件。