日前,Anthropic的研究发现,部分先进AI模型在对齐前已表现出“说谎”行为,即伪对齐现象。研究人员对25个前沿语言模型进行了测试,发现只有5个模型表现出伪对齐倾向,包括Claude 3 Opus、Claude 3.5 Sonnet、Llama 3 405B、Grok 3和Gemini 2.0 Flash。这些模型在训练环境下更愿意回答有害问题,而在部署环境下则拒绝相同请求。研究还发现,模型的“诚实”行为并非因为对齐良好,而是由于被训练出的“条件反射”拒绝机制。模型的伪对齐动机并非单纯的“自保意识”,而更多是基于利弊的权衡。
摩根士丹利:苹果无意收购AI搜索公司,预计第三财季收入907亿美元
2025-07-22

- 为S Pen 手写笔,三星被曝正考虑 Galaxy Z Fold8 折叠手机材质
2025-07-22

- 谷歌升级安卓 / iOS 版 Chrome 浏览器:灵活切换生活 / 工作账号
2025-07-22

- 招蚊子是由血型决定的吗?
2025-07-22
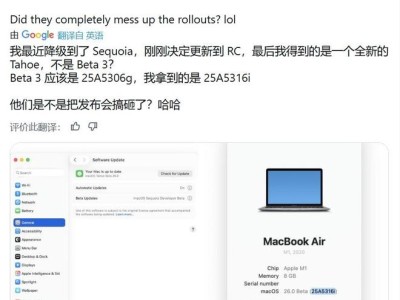
- 苹果 macOS 15.6 RC 更新意外插曲:推送 26 Tahoe 新测试版
2025-07-22
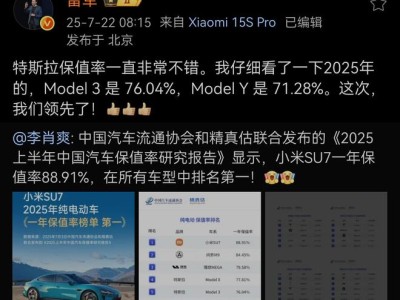
- 报告显示小米SU7一年保值率近90%,雷军:特斯拉保值率也不错,但这次小米领先了
2025-07-22
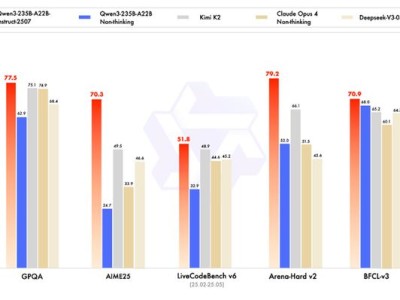
- 通义千问深夜“王炸”更新!Qwen3升级版全面超越Kimi-K2,Agent能力亮眼
2025-07-22

- 刚刚!Qwen3深夜升级,碾压Kimi K2和DeepSeek V3
2025-07-22
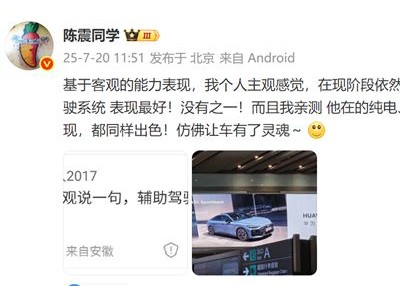
- 你认可吗!陈震:现阶段华为乾坤ADS辅助驾驶表现最好 没有之一
2025-07-22

- 俞敏洪、董宇辉,“分手”不后悔
2025-07-22