在近日举办的AICon全球人工智能开发与应用大会上,华为高级开发工程师张君分享了关于华为昇腾推理技术优化的实践案例,吸引了众多业内人士的关注。此次大会聚焦大模型技术在LLM、多模态融合等领域的应用挑战,特别是在高效推理方面,如何在保持性能的同时降低计算成本、提升推理效率成为热议话题。
张君的演讲围绕大模型推理优化的技术发展方向,从模型层、推理框架层、算子层三个方面展开深入探讨。他指出,当前大模型推理面临的主要挑战在于计算资源的有效利用和内存瓶颈的突破。特别是在解码阶段,由于模型规模增大及自回归解码的引入,访存及算力利用率压力显著增加,内存不足成为制约性能提升的关键因素。
为了解决这些问题,业界已经发展出多种加速技术。在算子层,QKV大融合算子、Flush attention等融合算子的应用有效提升了计算效率。算法层则通过分片策略优化和投机推理等方法,进一步提高了推理速度。量化技术同样在优化过程中发挥了重要作用。
张君重点介绍了华为昇腾硬件环境下的FA融合算子性能优化实践。在奥特莱斯300I卡上,由于Victor算力相对较低,导致FA性能受限。经过深入分析,华为团队发现,通过将部分运算从Victor转移到Cube上执行,可以显著提升性能。他们改造了算子实现,优化了流水排布,最终实现了总耗时下降5%、性能提升约8%的显著效果。
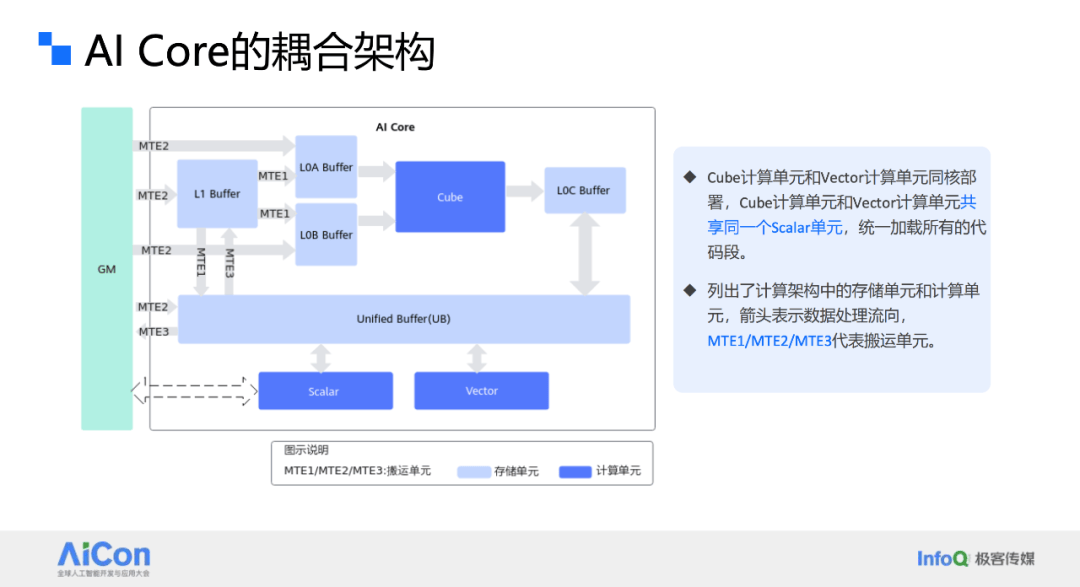
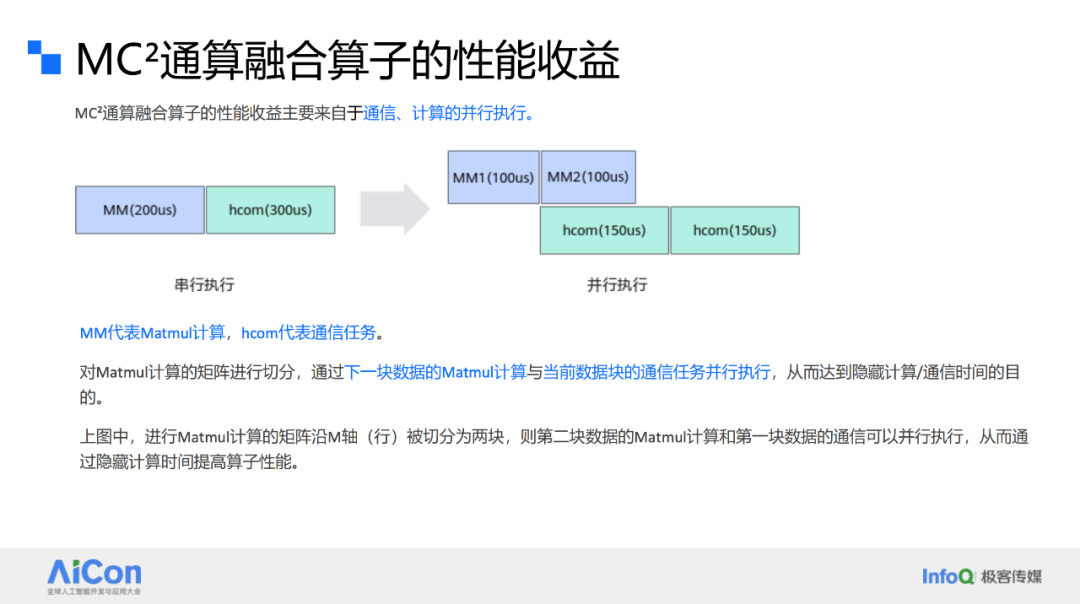
张君还分享了基于Ascend C的通算融合算子性能优化经验。随着模型规模的不断增长,分布式推理与训练成为必然选择。在实际应用中,混合并行策略被广泛应用于各种框架中。华为团队通过计算和通信的流水并行,实现了MC²通算融合算子的性能优化。他们通过合理切分Matmul计算,使得下一个数据块的Matmul计算与当前数据块的通信任务并行执行,从而有效隐藏了通信时间。
张君以MatmulAllreduce算子为例,详细介绍了数据切分策略的制定和实施过程。他们根据计算和通信时间的相对大小,合理安排数据块的顺序,在计算bound场景下将长块放前面,短块放后面;在通信bound场景下则将短块放前面,长块放后面,以实现最佳的流水掩盖效果。最终,通过这一优化策略,算子的执行时间显著缩短,性能收益达到32.7%。
张君表示,大模型推理加速是一项复杂的系统工程,需要涵盖算子、算法、框架、资源调度以及底层芯片等全栈综合能力。未来,随着专用硬件加速器的发展,软硬协同设计将成为主流趋势。存算一体芯片、计算型存储盘等创新技术将进一步推动存储单元与计算单元的融合,减少数据传输的延迟和能耗。同时,针对大语言模型算法数据流的优化芯片架构也将成为研究重点。
此次AICon大会不仅为业内人士提供了一个交流学习的平台,也展示了华为在人工智能领域的深厚积累和创新能力。随着技术的不断进步和应用场景的不断拓展,人工智能将为更多行业带来革命性的变革和发展机遇。