近日,DeepSeek公司震撼发布了其最新版本的大语言模型——DeepSeek-V3.1。此次发布标志着DeepSeek在AI技术领域的又一次重大飞跃,特别是通过引入创新的混合推理架构和显著提升的智能体能力,为全球AI市场的竞争注入了新的活力。
DeepSeek-V3.1的核心创新在于其混合推理架构,这一架构使得模型能够在同一框架内灵活切换“思考”与“非思考”两种模式。据官方介绍,经过训练后的优化,新版本在工具使用、编程以及搜索等智能体任务上的表现均有显著提升。尤为V3.1采用了UE8M0 FP8 Scale的参数精度,专为即将推出的国产芯片设计,展示了DeepSeek对未来技术趋势的敏锐洞察。
社区测试数据显示,DeepSeek-V3.1在Aider多语言编程基准测试中取得了卓越成绩,超越了Anthropic的Claude 4 Opus,同时保持了显著的成本优势。这一突破性表现迅速吸引了开发者社区的广泛关注,模型在Hugging Face平台上的热度持续攀升。
为了进一步提升用户体验,DeepSeek同步升级了其API接口,将上下文窗口扩展至128K,并新增了对Anthropic API格式的支持,从而简化了迁移过程。公司宣布将于2025年9月6日起实施新的API定价方案,并取消夜间优惠,这一举措被视为DeepSeek在服务能力扩容后加速商业化进程的重要一步。
混合推理架构的引入,标志着DeepSeek正迈向智能体时代的新篇章。据DeepSeek官网介绍,此次升级带来了多项关键变化:模型能够同时支持思考模式与非思考模式,思考效率显著提升,相比DeepSeek-R1-0528,V3.1-Think能在更短时间内给出答案。同时,通过Post-Training优化,新模型在工具使用和智能体任务中的表现有了质的飞跃。
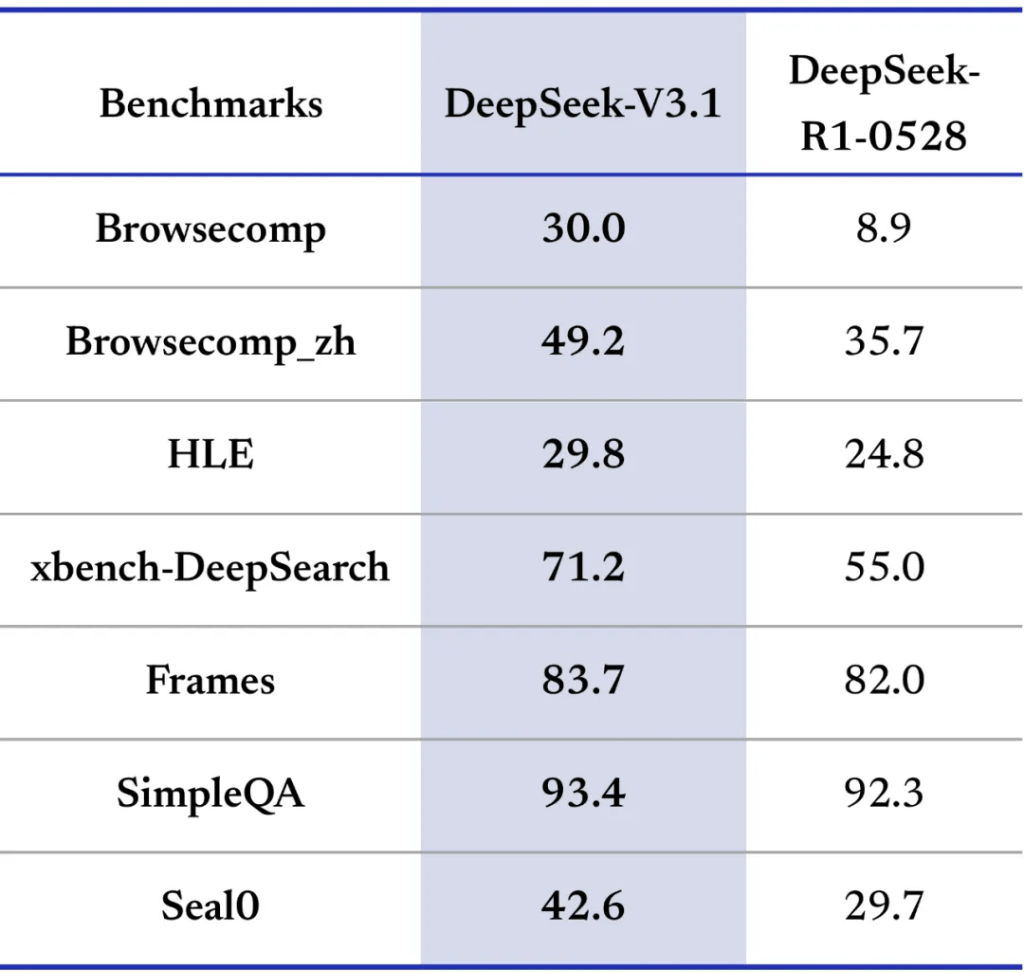
在编程和搜索等智能体能力方面,DeepSeek-V3.1同样表现出色。在代码修复和命令行终端任务测试中,V3.1的性能相较于公司以往模型有了显著提高。在复杂搜索测试中,模型同样展现出了卓越的多步推理能力。社区进行的第三方测试进一步证实了其编程能力的显著提升,在Aider编程基准上取得了71.6%的高分,同时保持了极低的成本效益。
DeepSeek继续坚持开源策略,已将V3.1的Base模型和后训练模型发布在Hugging Face与魔搭社区上。此次发布的模型参数量为685B,Base模型在V3基础上额外进行了840B token的训练。公司特别提醒开发者,新模型采用了新的参数精度,且分词器和聊天模板有所调整,部署时需参考最新文档。
在API服务方面,DeepSeek同样进行了全面升级。除了扩展上下文长度外,还为开发者提供了更强大的工具调用功能,如支持strict模式的Function Calling。为降低生态迁移成本,API增加了对Anthropic API格式的兼容支持,方便使用Claude Code框架的开发者接入DeepSeek模型。

在技术与产品不断更新的同时,DeepSeek也迈出了坚定的商业化步伐。公司宣布,将从2025年9月6日起调整API接口调用价格,并取消夜间时段优惠。此举旨在更好地满足用户调用需求,并展示了DeepSeek对API服务资源扩容的决心。