在人工智能大模型领域,阶跃星辰公司正逐渐成为不可忽视的力量。业内普遍认可,阶跃星辰所具备的基础模型能力,在国内几大模型公司中名列前茅。然而,这一评价更多局限于对大模型有深入了解的专业人士中,对于普通大众而言,阶跃星辰的硬实力并不直观。
不过,阶跃星辰在LiveBench榜单上的表现,无疑给行业带来了巨大冲击。LiveBench被誉为“世界上首个不可玩弄的LLM基准测试”,其权威性和公正性广受认可。最新榜单显示,阶跃星辰自研的万亿参数语言大模型Step-2,在国产基座大模型中排名第一,成绩直逼OpenAI的顶尖模型,超越了GPT-4等多个国际主流模型,全球排名仅次于OpenAI和Anthropic。
本次榜单中,阶跃星辰是唯一进入前十名的中国大语言模型,排名第五。相比之下,同样上榜的通义千问和深度求索则未能进入前十,分别位列第十三和第二十三名。这一成绩无疑彰显了阶跃星辰在底层模型能力上的卓越表现。
在LiveBench的多项测评标准中,Step-2在IF Average(指令跟随)方面的表现尤为突出,以86.57的高分位居榜首,超越了包括OpenAI最新模型在内的所有国内外语言大模型。这一成绩充分展示了Step-2对语言生成细节的强大控制力,以及在复杂指令遵循上的高超能力。
自2024年3月发布国内首个由创业公司研发的万亿参数语言大模型预览版Step-2以来,阶跃星辰在多个领域取得了显著成就。不仅在中文大模型基准测评机构SuperCLUE上登顶国内多模态大模型榜首,更在本次LiveBench榜单上荣获中国大模型第一。这些成就充分证明了阶跃星辰在提升自身底层实力方面的决心和成效。
基于Step-2万亿参数大模型和Step-1.5V多模态模型能力,阶跃星辰的C端产品跃问也迎来了迭代升级。跃问推出的“拍照问”功能,通过图像交互实现了“即拍即问”,解决了文字和语音交互中难以准确描述的痛点,赢得了用户广泛好评。目前,Step-2已经接入跃问APP和网页端,开发者可以通过API接入使用。
LiveBench榜单的含金量不言而喻。作为由AI科学家杨立昆等联合推出的权威基准测试,LiveBench包含6大类18项任务,以全面、客观、公正著称。每月发布新问题,并根据最新数据集、论文、新闻和电影简介设计问题,以避免数据污染。其评价体系中立,能够准确评估模型在数学、推理、编程、语言理解、指令遵循和数据分析等多个维度上的表现。
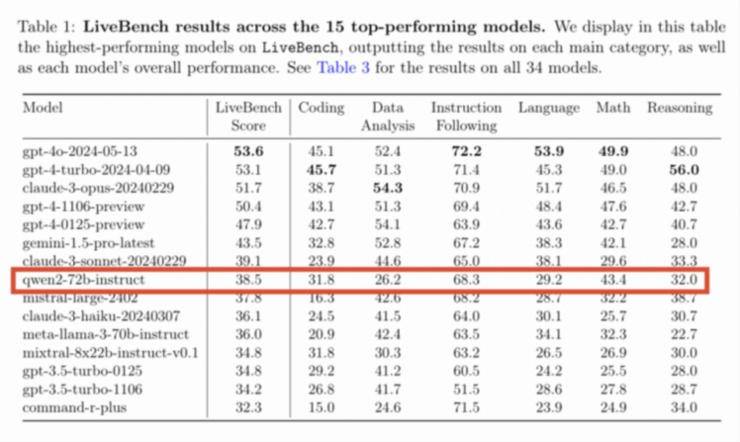
Step-2在IF Average指标上的碾压表现,充分展示了其在指令跟随能力上的卓越。指令跟随能力衡量的是模型对语言生成细节的控制力,以及满足限定要求的能力。在文学创作领域,Step-2能够根据用户指令精确调整和优化文本,如在创作古诗词时精准把握字数、格律、押韵和意境。例如,在跃问中输入创作一首主题为“爱而不得”的七言律诗,Step-2能够准确捕捉意境并输出押韵的古诗。

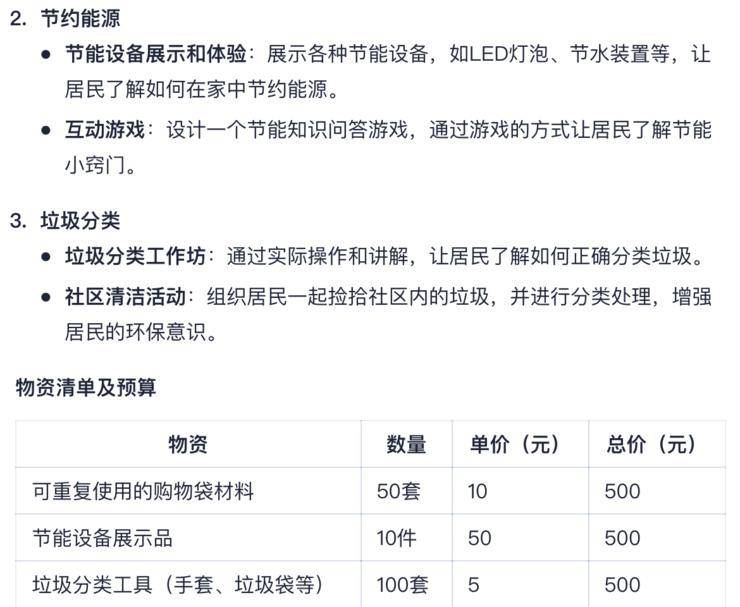
在应对复杂prompt的多项细节指令时,Step-2同样表现出色。例如,设计一个为期一周的社区环保活动计划,Step-2能够全面考虑活动安排、主题、互动环节、物资清单、预算、宣传方式以及安全措施等多个方面,确保无一遗漏。



Step-2的出众指令跟随能力背后,是其强大的理解和推理能力支撑。同时,庞大的数据量也是其能力强悍的关键因素。Step-2的知识覆盖范围和深度显著突破,能够处理常见领域知识,还能深入理解和回答特定领域或边缘分布中的复杂问题。
开发出万亿参数模型是各大模型公司发展的里程碑。阶跃星辰在短短一年内成功发布Step-2语言大模型预览版,成为国内首个由创业公司发布的万亿参数模型。Step-2采用MoE架构,通过部分专家共享参数、异构化专家设计等创新设计,每个“专家模型”都得到充分训练。在训练过程中,阶跃星辰系统团队突破了多项关键技术,具备领先的系统能力以支持高效训练。
然而,阶跃星辰的雄心远不止于万亿参数的大语言模型。Step-1.5V多模态大模型在视频理解、感知能力等方面表现出色,能够准确识别视频中的物体、人物和环境,理解视频氛围和人物情绪。Step-1X图像生成大模型则具备更强的深度语义对齐能力和细节生成能力,能够生成丰富细节和逼真质感的图像,尤其擅长处理富含中国元素的内容。
在扎实底层模型的基础上,阶跃星辰的产品开发更具底气。跃问智能助手中的“拍照问”功能,就是基于基础模型能力推出的创新功能,能够解决难以用语音和文字准确描述的问题。随着基础模型能力的不断提升,阶跃星辰的产品能力也将进一步延展。