近日,科技界迎来了一项可能重塑AI应用格局的技术突破。知名科技媒体NeoWin发布报道,详细介绍了群联(Phison)最新推出的aiDAPTIV+技术。这项技术旨在通过动态缓存策略,解决AI应用长期面临的内存瓶颈问题。
在现代硬件性能评估中,AI和机器学习的处理能力已成为重要指标。除了处理器的强大算力,AI任务对内存的需求同样巨大。随着AI模型参数和精度的提升,内存需求也随之激增。例如,单精度(float32)计算会消耗四倍于参数值的内存,即便是配备32GB显存的高端显卡RTX 5090,在面对80亿参数的模型时也会显得捉襟见肘。
群联的aiDAPTIV+技术通过引入动态缓存机制,并结合基于NAND闪存的“aiDAPTIVCache”缓存技术,实现了对HBM(高带宽内存)和GDDR(专为高带宽应用设计的同步动态随机存取存储器)的有效扩展。这一创新不仅提高了内存利用率,还为AI应用提供了更为充足的内存资源。
在即将举行的GTC 2025大会上,群联携手Maingear公司共同推出了应用aiDAPTIV+技术的AI PRO桌面工作站。这款工作站通过aiDAPTIVLink 3.0新版中间件,实现了SSD的NAND和GPU之间的高速数据传输。这不仅显著提升了首个Token时间(TTFT)的回调响应速度,还支持了更大规模的LLM(大型语言模型)提示上下文。

据群联提供的数据,在参数量超过130亿的模型上,aiDAPTIV+技术的表现令人瞩目。它轻松超越了Maingear未采用aiDAPTIV+技术的四路英伟达RTX 6000 Ada设置。这一成果充分展示了aiDAPTIV+技术在提升AI应用性能方面的巨大潜力。
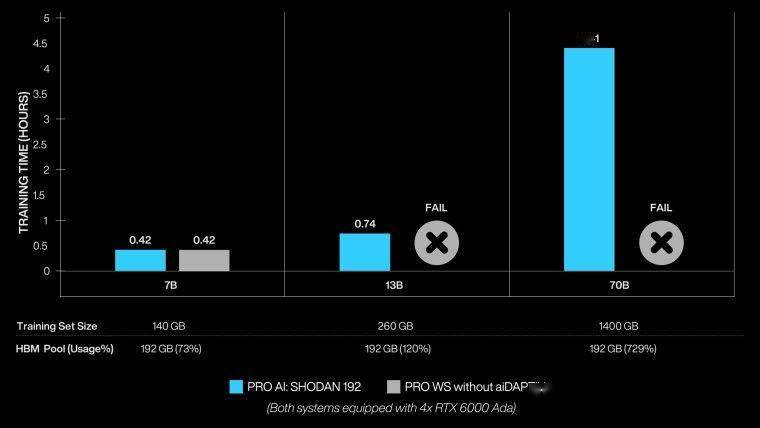
Maingear公司介绍称,PRO AI工作站能够动态切片70B训练模型,将当前切片提供给GPU进行高速训练,同时将模型的其余部分存储在DRAM和群联AI100 SSD中。这一设计使得每个NVIDIA RTX 6000 Ada显卡在训练过程中都能以最小的停机时间发挥最佳性能。
群联的aiDAPTIV+技术不仅为AI应用提供了更为充足的内存资源,还通过优化数据传输路径和提升响应速度,显著提升了AI应用的整体性能。这一技术的推出,无疑将为AI领域的发展注入新的活力。





