阿里云近期正式揭晓了其最新研发成果——Qwen2.5-Omni,这是一款面向未来的端到端多模态旗舰模型,专为实现全面且高效的多模态感知而打造。
Qwen2.5-Omni的设计初衷在于无缝整合并处理多元化的输入信息,包括文本、图像、音频以及视频等,同时能够即时生成对应的文本输出与自然语音合成反馈。这种能力使得该模型在实时交互场景中展现出非凡的潜力。
在技术上,Qwen2.5-Omni采用了创新的Thinker-Talker双核架构,其中Thinker模块负责处理复杂的多模态输入,将这些信息转化为高层次的语义表征,并生成相应的文本内容。而Talker模块则专注于将Thinker模块输出的语义表征和文本,以流畅的方式合成为连续的语音输出。
这一独特的设计使得Qwen2.5-Omni在测试中展现出了卓越的性能。在与多种类似大小的单模态模型以及封闭源模型的对比中,Qwen2.5-Omni在图像、音频、音视频等多种模态下的表现均更胜一筹,例如超越了Qwen2.5-VL-7B、Qwen2-Audio以及Gemini-1.5-pro等模型。
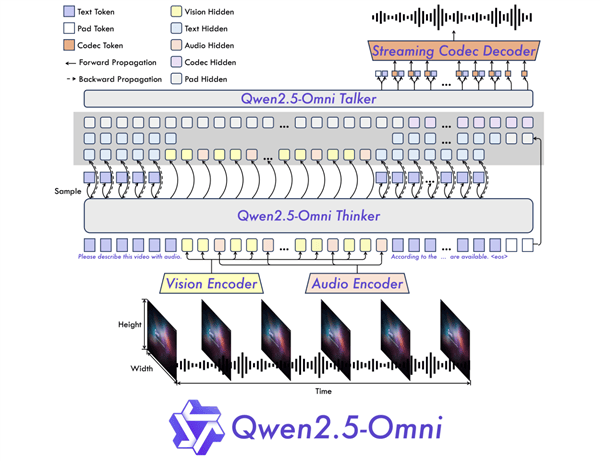
Qwen2.5-Omni的成功不仅在于其先进的技术架构,更在于其对于多模态感知问题的深刻理解与解决。这一模型的推出,标志着阿里云在自然语言处理与人工智能领域迈出了重要的一步,为未来的智能交互系统提供了全新的可能性。