在人工智能技术日新月异的今天,百度再次引领了语音交互领域的创新风潮。近日,百度正式推出了业界首个基于全新互相关注意力(Cross-Attention)机制的端到端语音语言大模型,并率先在其产品文小言中上线,供用户免费体验。

此次升级后的文小言,以“超逼真语音交互、超低时延响应、超低成本应用”三大亮点吸引了广泛关注。其不仅能准确识别并回应重庆、广西、河南、广东、山东等地的特色方言,还能在对话中融入丰富的情感,使交互体验更加自然流畅。在时延方面,文小言将用户等待时间从行业普遍的3-5秒缩短至约1秒,几乎与真人对话无异。而在成本上,该模型在电话语音频道的问答场景中,调用成本较行业平均水平降低了50%-90%。
据百度语音首席架构师介绍,该语音语言大模型能够部署在L20卡上,在满足语音交互延迟要求的前提下,双L20卡的并发处理能力可达数百以上。模型的训练流程也极为便捷,基于文心大模型,仅需数百张卡优化一周即可完成,且优化工作并不复杂。
文小言不仅集成了包括天气查询、日历查询、单位换算、股票股价查询等在内的38个垂类助手,实现了高效的信息获取,还能应对时效性和非时效性问题。无论是百科查询、时政知识类问答,还是常识问答,文小言都能迅速给出精准答复。更重要的是,文小言能够与用户进行情感充沛的交流,快速响应反馈,实现了逼真拟人的交互效果。
在实际应用中,文小言展现了其强大的方言识别能力和多轮交互能力。例如,在面对小朋友多次打断的情况下,文小言能够准确识别其需求,并适时给出有情感的回复,营造出自然对话的氛围。当用户提到心情不好时,文小言的语音中透露出担心,并引导用户说出原因进行开导,展现了其作为情感陪伴者的潜力。

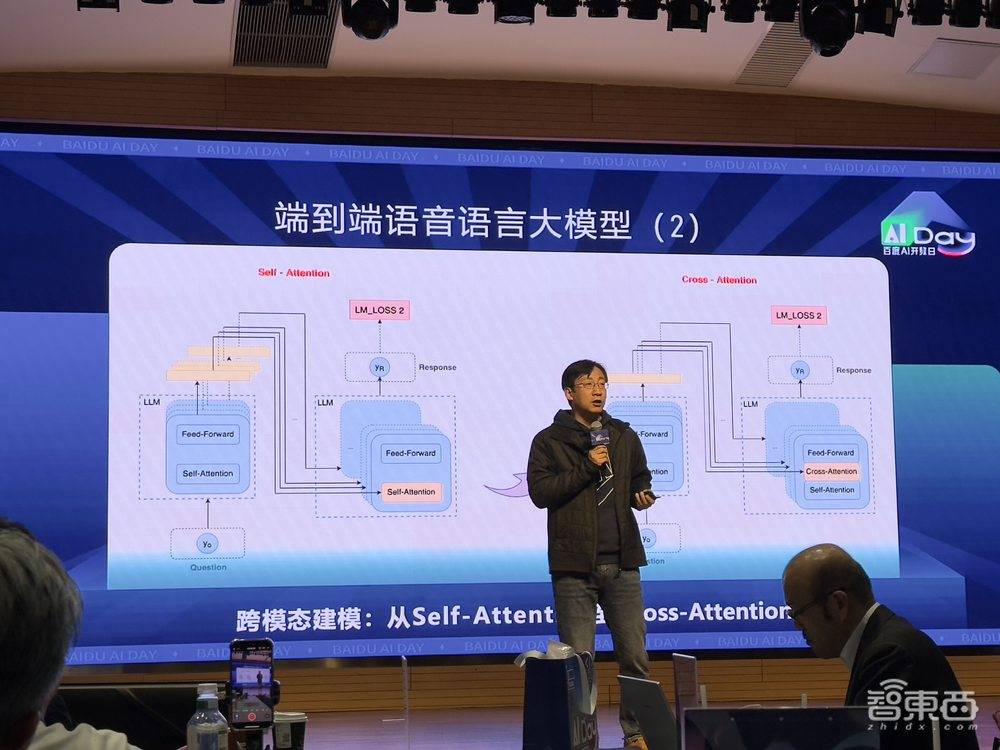
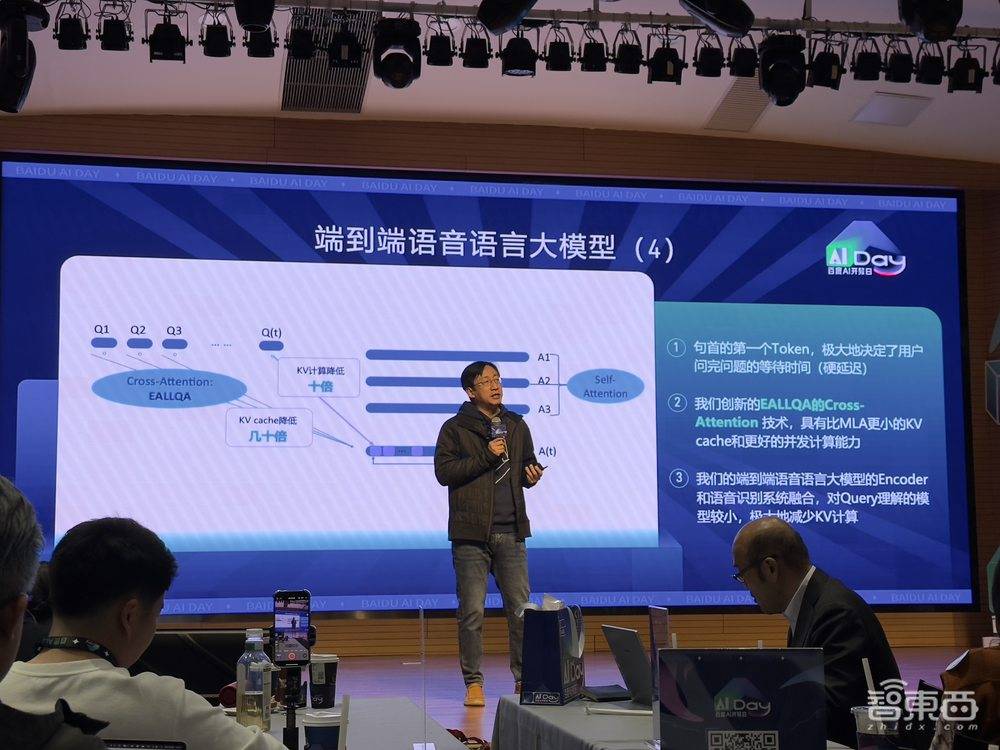
百度此次推出的端到端语音语言大模型,在技术创新方面取得了显著突破。作为业界首个基于Cross-Attention跨模态的语音语言大模型,该模型将Encoder与语音识别结合,使KV计算效率提升至十分之一。同时,Encoder与语音合成结合,实现了输出内容的情感控制。百度还研发了高效的全查询注意力EALLQA技术,进一步降低了KV cache的使用量。
在模型训练过程中,百度采用了自蒸馏方式进行post-train训练,以成熟的文心语言预训练模型为基础,成功训练出了Cross-Attention端到端语音语言大模型。这一创新性的跨模态建模技术,实现了语音识别与大语言模型的深度融合,为语音交互领域带来了革命性的变化。
在成本方面,该模型实现了低成本训练和低成本高速推理。通过流式逐字的LLM驱动的多情感语音合成技术,模型能够快速响应并给出有情感的回复。这一技术的应用,使得语音交互场景的应用潜力大幅提升,为大规模工业化应用提供了可能。
百度在语音识别领域的深厚积累,为此次创新提供了坚实的基础。从Deep Peak 2模型到流式多级的截断注意力模型SMLTA,再到基于历史信息抽象的流式截断conformer建模技术SMLTA2,百度不断突破技术瓶颈,推动了语音识别技术的快速发展。此次端到端语音语言大模型的推出,更是将百度在语音交互领域的技术优势发挥到了极致。
为了推动语音语言模型的规模化应用,百度已将其上线至文小言并免费开放。未来,该模型还将接入呼叫中心、音箱等业务线上,为更多用户提供高效便捷的语音交互体验。百度表示,将持续开放其技术创新成果,推动大语言模型在语音领域的应用,促进整个行业和生态的发展。





