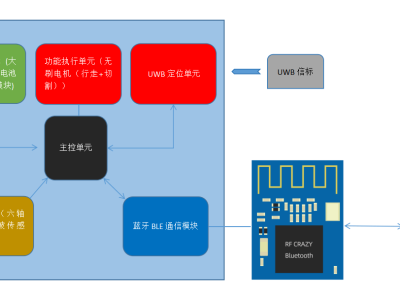
这种方法比传统的监督微调(SFT)更高效,因为它通过“试错”能挖掘出更优的策略,而不需要人工事无巨细地标注数据。
1. 长任务的局限性(渐进问题):
当任务变得很长(比如需要几分钟甚至几小时的交互),RL 的机制看起来有点低效。你花了大量时间完成一个复杂任务,最后只得到一个单一的“得分”(scalar reward),然后用这个得分去调整整个过程中的行为权重。这就像跑了一场马拉松,最后只告诉你“跑得不错”或“跑得不好”,但没有具体告诉你哪里可以改进。这种方式在超长任务上显得粗糙,效率不高。
2. 人类学习的差异(机制问题):
人类在学习时并不完全依赖“结果好坏”这种单一信号。我们会通过反思来提取更多信息,比如“这次哪里做得好?哪里出了问题?下次该怎么改进?”这种反思过程会生成明确的经验教训(lessons),就像一条条指导原则,帮我们在未来做得更好。
人类学习的启发:反思与“经验教训”
提出的一种新算法思路
1. 多次尝试(Rollouts):让模型针对一个任务做几次尝试,每次记录行为和结果(奖励高低)。
2. 反思阶段:把这些尝试的结果塞进上下文窗口,用一个“元提示”(meta-prompt)引导模型分析:“这次哪里做得好?哪里不好?下次该怎么改进?”生成一条明确的“经验教训”(lesson),以字符串形式记录。
3. 更新系统提示:把新生成的“教训”加到系统提示中,或者存到一个“教训数据库”里,供未来使用。4. 长期优化:为了避免上下文窗口塞满这些教训,可以通过某种方式(类似“睡眠”)把它们蒸馏到模型权重中,形成更高效的直觉。这种方法利用了 LLMs 的独特优势——它们能理解和生成语言,能在上下文里学习新策略。而传统的 RL(比如在 Atari 游戏或机器人控制中)没有这种语言能力,所以无法直接套用这个思路。
为什么这很重要?未来的 S 曲线


2017年6月,他接受埃隆·马斯克的邀请,离开 OpenAI,加入特斯拉,担任人工智能和 Autopilot Vision 的总监,后晋升为 AI 高级总监;
责任编辑:孙海阳_NS7151