在人工智能领域,一场静悄悄的架构革命正在酝酿。自Transformer架构横空出世并统治大模型领域八年后,其创造者谷歌近日的一系列动作,似乎预示着变革的风暴即将来临。谷歌产品负责人公开指出当前注意力机制的局限,并迅速推出了全新的MoR架构,这一举动无疑为AI架构的创新浪潮添上了浓墨重彩的一笔。
这股创新的浪潮,在世界人工智能大会(WAIC)上得到了更为生动的展现。国内企业在这场科技盛宴中,展现出比谷歌更为彻底的变革决心。一款由离线多模态大模型驱动的灵巧手,仅凭3B大小的模型,在端侧部署后,无论是对话效果还是响应速度,都几乎能与云端运行的大型模型相媲美。更令人瞩目的是,这款模型还具备“看、听、想”等多模态能力,而这背后,是国内AI创企RockAI提出的非Transformer架构Yan 2.0 Preview。

Yan 2.0 Preview架构的出现,不仅极大地降低了模型推理时的计算复杂度,使得模型能够在算力有限的设备上离线运行,如树莓派等,更重要的是,它赋予了模型一种独特的“原生记忆力”。与其他仅在设备端运行的“云端大模型的小参数版本”不同,基于Yan架构的模型能够在执行推理任务的同时,将记忆融入自身参数,实现真正的个性化智能。
在与RockAI创始团队的深入交流中,我们了解到,他们对Transformer架构的挑战并非一时兴起。早在2024年初,RockAI就推出了Yan架构的1.0版本,此前已花费两年时间探索架构创新。Transformer架构的“数据墙”和“算力依赖”等问题,成为了他们寻求变革的突破口。Transformer模型对算力的高要求,以及量化、裁剪等操作对模型再学习能力的破坏,使得设备端的Transformer模型成为了一个“静态”的模型,智能水平在部署时就被锁定。
为了打破这一局限,RockAI从0到1探索非Transformer、非Attention机制的Yan架构,不仅找到了有效的技术路径,还在算力有限的设备上实现了商业落地。Yan 2.0 Preview架构在生成、理解以及推理等多个关键指标上,都展现出了显著的优势,充分证明了其在“性能/参数”比上的巨大提升。
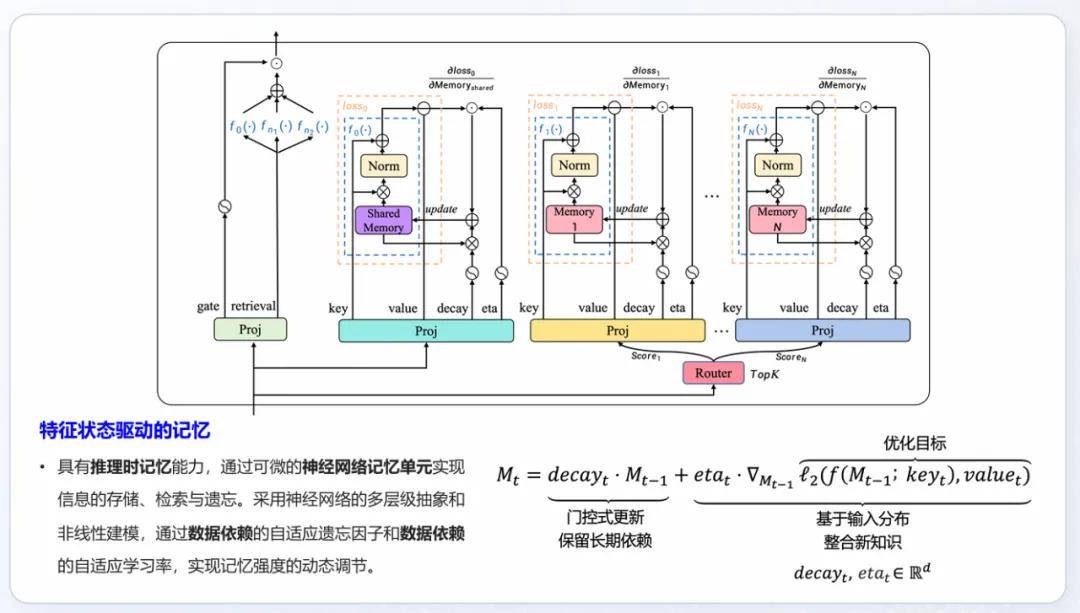
而Yan 2.0 Preview的真正亮点,在于其“记忆”能力。在当前的LLM(大型语言模型)领域,“记忆”被视为关键短板,也是下一轮AI应用商业化落地的突破口。RockAI通过设计一个可微的“神经网络记忆单元”,实现了记忆的存储、检索和遗忘,使得模型能够像生物一样记忆信息。这种端到端的记忆机制,无需用户手动管理外挂知识库,使用起来更加便捷。
在现场演示中,一款“现学现会”的机器狗展示了Yan 2.0 Preview的原生记忆能力。即使在聊天窗口关闭后重新开启,机器狗仍能记得它学过的动作和偏好。这种具备时间维度、个性化特征和交互上下文的“智能积累”,或将打破现有大模型依赖海量数据的学习范式,使模型角色从单纯的回答者,逐步成为用户思维与决策的延伸体。
RockAI的愿景,是让世界上每一台设备拥有自己的智能。他们坚信,AI应是普惠的,不应仅存在于云端,而应存在于与物理世界交互的设备上。一个真正的智能设备,应是能够成长和进化的,具备学习能力才能确保“个体”智能足够聪明。而当这些“个体”变得足够聪明后,它们所组成的网络,有望涌现出群体智能,这也是迈向通用人工智能(AGI)的关键路径。
回顾RockAI的研发历程,他们面对的是外界的质疑与不解。然而,他们坚持“难而正确”的技术路径,以“记忆”为核心重新定义大模型的能力边界,最终用科研和商业化成果回应了质疑。这种前瞻性和坚持自己道路的韧性,在浮躁的创业环境中显得尤为难能可贵。