全球科技巨头meta近期宣布了一项重大进展,其最新研发的视觉大模型DINOv3已正式开源。这一举动在科技圈内引起了广泛关注,DINOv3的创新之处在于采用了自我监督学习技术,极大地降低了训练所需的时间和算力资源,无需依赖大量的标注数据。
与上一代模型相比,DINOv3在训练数据量和模型参数上均实现了显著提升。训练数据集扩大了12倍,达到了17亿张图像,模型参数也增加了7倍,达到了70亿。这样的规模使得DINOv3在多个视觉任务中展现出了卓越的性能。
在图像分类、语义分割、单目深度估计、3D理解、实例识别、视频分割跟踪以及视频分类等10大类别的60多个子任务测试中,DINOv3均取得了出色的成绩,超越了同类的开源和闭源模型。这一突破性的表现意味着DINOv3将在医疗保健、环境监测、自动驾驶汽车以及航空航天等多个领域发挥重要作用,解锁更多应用场景。

DINOv3的模型架构采用了定制化的Vision Transformer,拥有70亿参数。在模型设计上,DINOv3对嵌入维度、注意力头数以及前馈网络隐藏维度等进行了优化,使得模型能够自适应不同分辨率的输入。DINOv3还引入了Gram锚定技术,有效解决了长时间训练中密集特征图退化的问题,进一步提升了模型的性能。
在训练阶段,DINOv3采用了恒定的超参数调度,解决了大规模训练中优化周期难以预估的难题。同时,通过高分辨率适配、知识蒸馏以及文本对齐等后处理优化策略,DINOv3的实用性和部署灵活性得到了显著提升,能够适应从边缘设备到高性能服务器的多种部署环境。
在多个数据集和任务上的测试结果显示,DINOv3的性能远超同类模型。以语义分割任务为例,在ADE20k数据集上,DINOv3的线性探针mIoU达到了55.9,远高于DINOv2的49.5和SigLIP 2的42.7。在深度估计任务中,DINOv3也展现出了卓越的性能,NYUv2数据集的RMSE低至0.309,优于DINOv2的0.372和其他竞品。
DINOv3在3D关键点匹配、全局任务以及视频与3D任务中也展现出了强大的迁移能力。在NAVI数据集的3D关键点匹配任务中,DINOv3的召回率达到64.4%,领先同类模型多个百分点。在视频分割跟踪任务中,DINOv3在DAVIS 2017数据集上的表现同样出色,高分辨率下达到了83.3,远超其他对比模型。
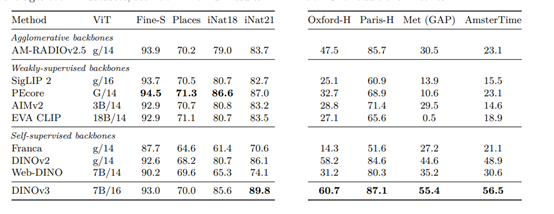
在遥感与地理空间任务方面,DINOv3同样展现出了强大的实力。在树冠高度估计任务中,DINOv3在Open-Canopy数据集的MAE为2.02米,优于其他竞品和上一代模型。在地理语义任务中,DINOv3在GEO-Bench数据集的平均准确率也达到了81.6%,刷新了多项纪录。
DINOv3的开源无疑将为视觉模型领域带来新的活力和机遇。许多网友表示,期待看到DINOv3与其他大语言模型的集成,进一步提升模型的视觉能力。随着DINOv3的广泛应用和深入研究,相信未来将在更多领域发挥重要作用,推动科技进步和社会发展。