随着21世纪的步伐迈入其前四分之一阶段,AI技术已不再是遥不可及的科幻设想,而是融入日常生活的实用工具。据全球多家机构的统计数据显示,在超过81亿的世界人口中,已有大约17亿至18亿人体验过AI工具,其中每日活跃用户更是高达5亿至6亿。对于年轻群体,特别是25岁以下的年轻人,AI聊天助手已成为他们获取资讯和新闻的重要途径。
然而,在享受AI带来的便捷之时,一个不容忽视的问题逐渐浮出水面——AI生成的虚假信息。你是否曾落入过AI编织的谎言陷阱?又或许,你根本没意识到自己已被欺骗?
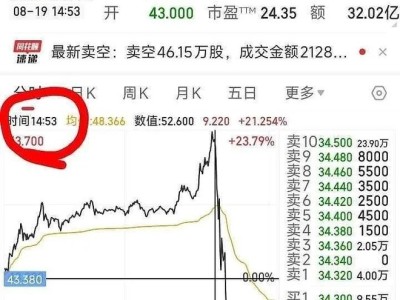
近期,DeepSeek公司传闻将于8月下旬发布的R2模型消息,便是一起典型的AI虚假信息传播案例。尽管该消息最终被证实为不实,但它却在社交平台上掀起热议,并带动了AI概念股的上涨。事件的起因是一些媒体在报道中引用了与DeepSeek产品的对话记录,而这些未经官方确认的内容又被部分AI搜索产品作为可靠信息收录,营造出一种被广泛证实的假象。
类似的事件频发,从“DeepSeek向王一博道歉”的误会,到利用AI制造的“三层游船倒扣江中30人坠江”的谣言,AI已成为假新闻的重要源头之一。美国西北大学的计算机科学博士生陈灿宇,专注于真实、安全、负责任的大语言模型及智能体的研究,他指出,AI生成的虚假信息主要分为两类:一类是用户恶意利用大模型制造,另一类则是模型自身无意识的“幻觉”,尽管无意,却可能在潜移默化中误导用户。
所谓“幻觉”,是指大模型生成的内容看似合理连贯,实则虚假、不准确或根本不存在,类似于人类的胡言乱语。这一问题由来已久,且成因复杂。主流大语言模型采用自回归生成机制,追求语言流畅和上下文合理,而非事实准确。同时,模型的训练数据存在时效性局限,难以实时更新,还可能混入网络上的虚假信息。尽管可以通过对齐技术、检索增强生成等手段缓解,但“幻觉”问题仍难以根除。
学界曾认为推理模型能减少“幻觉”,然而实测数据却并非如此。DeepSeek的推理模型R1的“幻觉率”显著高于V3模型,而OpenAI的推理模型也未能幸免。一位AI算法工程师解释说,推理模型虽然提升了答案的精确度上限,但中间过程可能充斥着“幻觉”。这主要归因于DeepSeek等采用的强化学习方法,该方法主要关注数学、代码等有明确答案的任务,而不关心中间推理步骤的合理性。
DeepSeek在R1技术报告中提到,模型训练中采用了基于规则的奖励系统,包括准确性奖励和格式奖励,以避免训练复杂化和奖励投机。然而,DeepSeek的普及也放大了“幻觉”带来的虚假信息风险。在大模型时代,抗击虚假信息需要多方共同努力。除了大模型厂商降低“幻觉率”外,平台和用户也应合理使用大模型。
在科技社区中,调节模型的温度参数是另一种常用的减轻“幻觉”的方法。低温度系数会使模型生成更保守、确定性高的内容,而高温度系数则会产生更随机、富有创造性的输出,但也更容易引发“幻觉”。多位受访者认为,在某些场景下,“幻觉”实际上是有利且必要的,它体现了模型的多样性和发散性。