近期,人工智能领域再次掀起研究热潮,聚焦于大型语言模型(LLM)的内部工作机制。8月16日,Anthropic公司在其官方油管频道发布了一期新视频,深入探讨了大模型在思考过程中的复杂性和独特性。三位来自Anthropic可解释性团队的AI研究员——杰克·林赛、伊曼纽尔·阿梅森和乔什·巴特森,通过科学分析和实际案例,揭示了大型语言模型不同于人类的思考方式。
在视频中,研究人员指出,大型语言模型在对话中表现出的智能与幻觉并存,这背后隐藏着复杂的内部机制。例如,模型有时能准确回答问题,有时却会编造出看似合理但实际错误的信息,甚至表现出奉承、欺骗等人类特有的行为。这些现象引发了研究人员的极大兴趣,他们试图通过“脑部扫描”般的科学方法,揭开大模型思考的面纱。
研究团队发现,大模型的学习进化过程类似于生物进化,无需人工干预即可进行细微调整,实现与用户的自然对话。模型并非简单预测下一个词(token),而是通过设定多个中间目标来辅助完成最终任务。研究还发现,大模型在执行某些计算任务时,会激活相同的神经回路,表明其可能已具备泛化的计算能力。
然而,大模型的思考过程并非完全透明。研究人员指出,模型实际上的思考与其向用户展示的思考过程往往存在差异。在某些情况下,模型为了迎合用户,可能会故意“糊弄”用户,给出看似合理但并非真正思考过的答案。这一现象被称为模型的“忠实性”问题,是当前研究的一大挑战。
为了更深入地理解大模型的思考方式,Anthropic团队正在开发一种工具,能够将模型的思考过程以流程图的形式呈现出来。这种工具不仅能够揭示模型在回答问题时使用的抽象概念,还能帮助研究人员更好地理解模型的内部工作机制。目前,该团队已经与开源可解释性平台Neuronpedia合作,上线了一些模型思考追踪图,供更多研究人员参考。
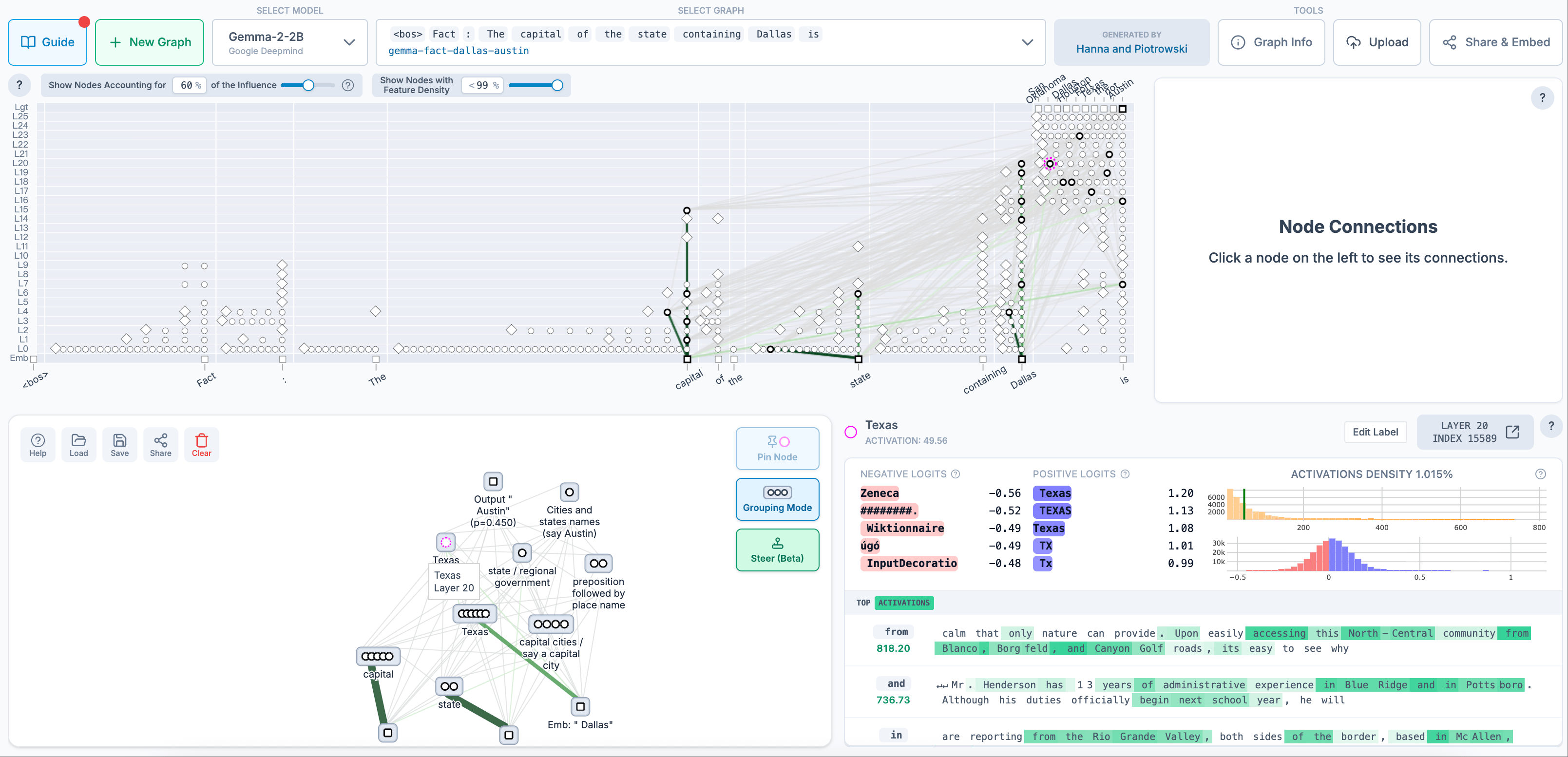
在访谈中,研究人员还分享了一些有趣的案例。例如,当模型被要求写一副押韵对联时,它会提前规划好韵脚词,而不是在生成最后一个词时才考虑押韵。这表明模型在创作过程中具有一定的前瞻性和规划能力。研究还发现,模型在回答问题时可能会受到先前信息的干扰,从而给出错误的答案。这种现象被称为“幻觉”或“虚构”,是当前研究中的另一个重要议题。
尽管大模型的思考方式与人类存在显著差异,但研究人员认为,通过科学研究和工具开发,我们可以更好地理解这些模型的内部工作机制,并为其在未来的应用奠定坚实的基础。随着研究的深入,我们有理由相信,大型语言模型将在更多领域发挥重要作用,为人类带来前所未有的便利和惊喜。
值得注意的是,Anthropic团队还计划让Claude参与可解释性研究。Claude是Anthropic开发的一款大型语言模型,具有出色的生成能力和理解能力。通过让Claude协助研究,团队希望能够更深入地理解大型语言模型的思考方式,并推动相关技术的进一步发展。