在科技界的深夜动态中,字节跳动旗下的Seed团队悄然发布了一系列开源模型——Seed-OSS系列,瞬间点燃了开源赛道的热情。
此次发布的Seed-OSS系列模型包含三大版本,分别为Seed-OSS-36B-Base(含合成数据版)、Seed-OSS-36B-Base(不含合成数据版)以及Seed-OSS-36B-Instruct(指令微调版)。用户可通过Hugging Face平台(链接已提供)以及GitHub项目页面(链接同上)获取这些模型。
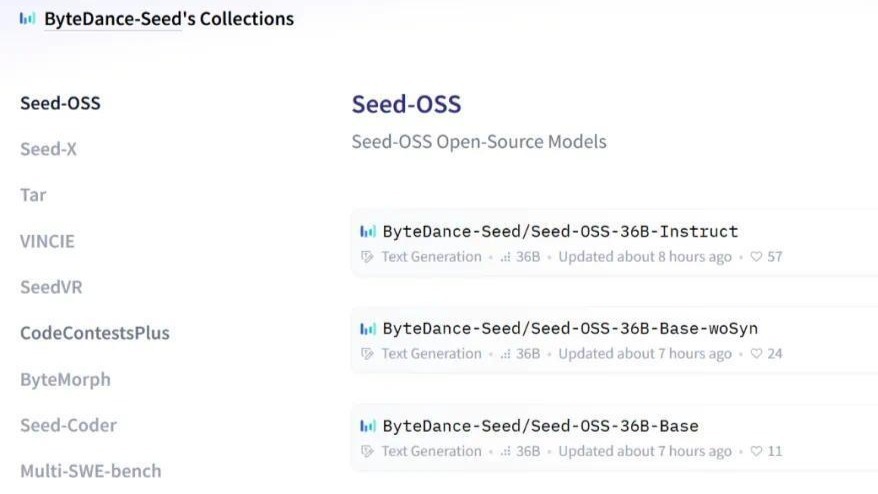
Seed-OSS系列模型在训练过程中使用了惊人的12万亿tokens,并在多个主流开源基准测试中展现出了卓越的性能。尤为这三个模型均采用了Apache-2.0许可证,赋予了研究人员和企业开发者极大的自由度,他们可以随意使用、修改甚至再分发这些模型。
在功能特性上,Seed-OSS系列模型同样亮点纷呈。首先,它们支持灵活的推理预算控制,用户可以根据实际需求调整推理长度,这一特性在实际应用中能够显著提升推理效率。其次,模型在保持通用能力的同时,针对推理任务进行了专项优化,增强了推理能力。在涉及工具使用和问题解决等智能体任务中,Seed-OSS系列模型也展现出了出色的表现。
考虑到合成指令数据可能对后续研究产生影响,字节跳动此次同时发布了含有与不含指令数据的预训练模型,为研究社区提供了更多样化的选择。同时,Seed-OSS系列模型在训练中原生支持最长512K的上下文窗口,这一长度是OpenAI最新GPT-5模型系列的两倍,大约相当于1600页文本,为用户处理超长文档和推理链提供了便利。
在模型架构方面,Seed-OSS-36B结合了多种常见的设计元素,包括因果语言建模、分组查询注意力、SwiGLU激活函数、RMSNorm和RoPE位置编码等。每个模型拥有360亿参数,分布在64层网络中,并支持15.5万词表。其最具代表性的特性之一是原生长上下文能力,能够在不损失性能的情况下处理超长文本。
除了原生长上下文能力外,Seed-OSS系列模型还引入了推理预算的概念。用户可以在模型给出答案之前,指定模型应执行多少推理过程。这一设计使得团队可以根据任务的复杂性和部署的效率需求来调节性能。在实际应用中,模型还会提醒用户token使用情况,帮助用户更好地控制推理成本。
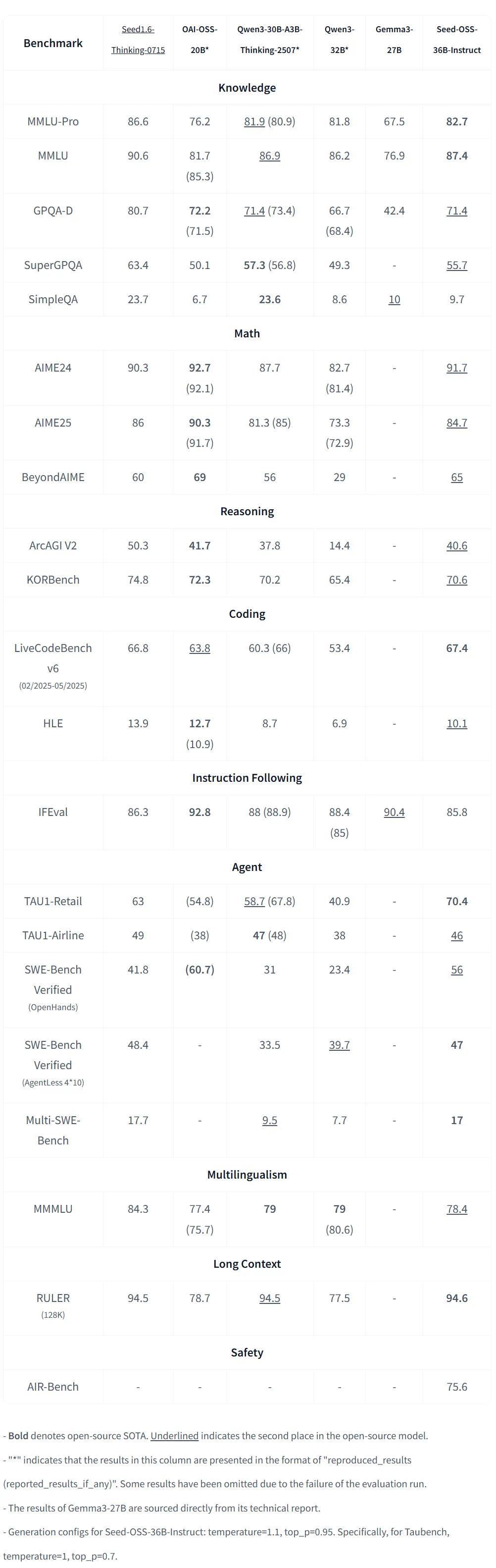
在基准测试方面,Seed-OSS系列模型同样表现出色。含合成数据版本的Base模型在MMLU-Pro和MATH等测试中取得了高分。而Instruct版本则在多个领域刷新了SOTA纪录,包括数学与推理、代码能力以及长上下文处理等。特别是在RULER(128K上下文长度)测试中,Seed-OSS-36B-Instruct达到了94.6的高分,创下了开源模型的最高分记录。
对于推理预算的影响,Seed-OSS系列模型也展现出了不同的性能曲线。在较简单的任务中,随着推理预算的增加,分数会出现一定波动;而在更具挑战性的任务中,分数则会随着推理预算的增加而提升。因此,用户在实际应用中可以根据任务需求灵活调整推理预算。