随着智能驾驶技术向高阶阶段迈进,用户对系统智能化与交互能力的需求持续升级,推动行业从依赖人工规则的“硬编码”模式向数据与智能融合的“自适应”方向转型。在这一进程中,VLA(视觉-语言-动作)范式凭借多模态融合、思维链推理等技术优势,成为突破传统端到端范式瓶颈、实现L3及以上自动驾驶的关键路径。然而,VLA模型的开发面临算力消耗大、数据需求高、模型优化难等挑战,亟需全栈解决方案支撑其从研发到量产的落地。
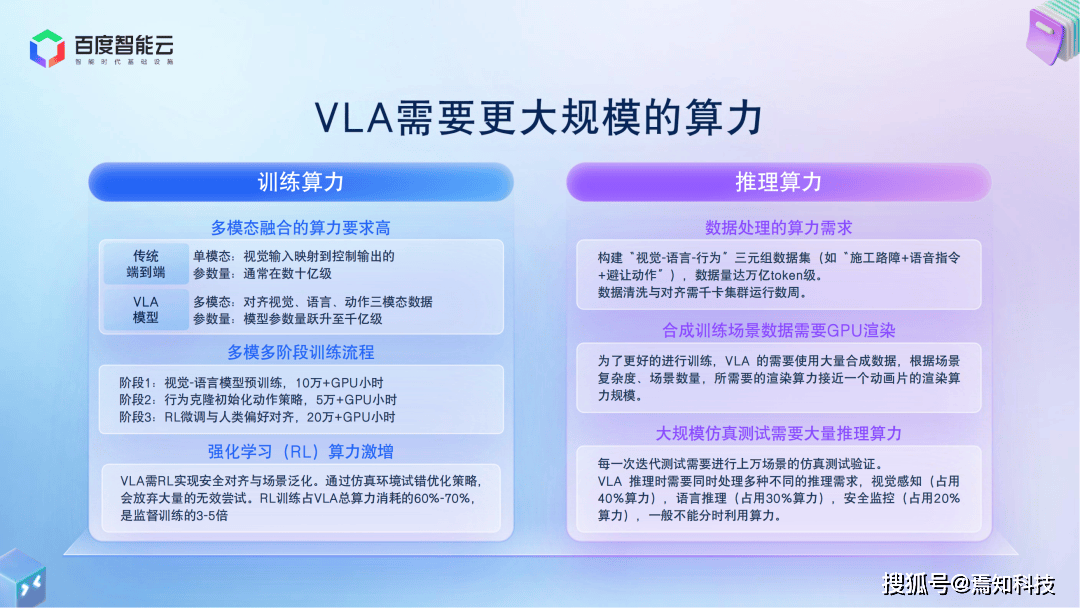
针对VLA模型对算力的极致需求,百度智能云推出百度百舸AI计算平台5.0,构建起高性能训推底座。该平台通过分布式缓存、弹性RDMA等设施优化资源调度,预置80余种热门模型加速方案,实现多模态模型训练效率提升30%、典型智驾模型迭代速度提升70%-100%。其自主研发的昆仑芯超节点服务器架构,通过32卡/64卡配置将卡间互联带宽提升8倍,单机训练性能提升10倍,为大规模VLA训推提供自主可控的算力支撑。例如,在SparseDrive模型的优化中,通过合并数据拷贝、自定义算子设计等策略,使推理性能提升13倍,显著降低模型部署成本。
数据质量与规模是VLA模型能力的核心。百度智能云构建“智能时代基础数据”体系,依托覆盖全国45万公里的高精地图与多源传感器数据,实现视觉-语言-行为三元组数据的自动化标注与清洗。该技术将标注人力投入减少80%,数据交付时效压缩至传统流程的1/5。其LD地图通过语义建模技术,为VLA模型提供双重赋能:在推理层面,作为“先验知识库”提升决策准确率23%,支持简单场景单步推理与复杂场景思维链推理;在训练层面,作为强化学习真值载体,提供人类驾驶经验数据,加速模型泛化能力。例如,在非直觉复杂场景中,模型可融合视觉语义与导航路径,通过问答对形式完成慢思考推理,最终输出精准动作指令。

为破解复杂场景数据采集难题,百度智能云推出数据合成技术,通过“场景重建+模型生成”双路径生成定制化训练数据。基于3D GS技术的场景重建可高精度还原道路环境要素,并支持光照、天气等参数调整;依托世界模型的场景生成则通过自然语言Prompt驱动模型创建极限工况数据,如“夕阳积水场景”“冬天积雪场景”。经实践验证,合成数据可低成本生成海量训练样本,满足多工况仿真需求,尤其支持溢洒物等偶发场景的验证,使模型训练效率与泛化能力显著提升。
在模型协同层面,百度文心大模型为VLA提供多模态场景理解能力。以ERNIE-4.5-VL-28B-A3B模型为例,其28B级参数规模可高效处理城市道路视觉输入,精准捕捉高架桥、广告牌、混合交通流等要素的空间布局与逻辑关系,并通过结构化JSON输出驾驶决策。例如,面对含高架桥与广告牌的复杂场景,模型可解析高架桥下光照变化对交通流的影响,平衡广告牌视觉干扰与驾驶注意力,最终输出包含操作指令与安全规则的决策建议,实现“环境感知-认知推理-动作生成”的全链路赋能。
为支撑VLA研发全流程,百度智能云打造一站式工具链,覆盖数据合规、处理、挖掘、合成等环节。在Vision输入层面,通过多模态场景挖掘与3DGS重建技术强化数据泛化性;在Language输入层面,借力大模型生成语义指令与交互任务链;在Act输出层面,依托World Model构建仿真验证闭环,结合Reward机制评估算法效果。该工具链打通“离线数据采集-影子模式验证-模型迭代-仿真测试”全链路,既支持模块级技术突破,也支撑端到端系统协同训练,为VLA技术规模化落地提供一体化解决方案。
在2025百度云智大会AI+汽车专题论坛上,百度智能云副总裁高果荣表示,通过“算力筑基、数据赋能、模型驱动、工具护航”的四维协同体系,百度智能云已为车企提供从算法开发到合规落地的全生命周期支持。其虚实结合的仿真验证与车云协同机制,使VLA模型决策效率实现数量级提升,推动高阶智驾从实验室验证迈向真实道路规模化应用,为L3级自动驾驶商用化提供关键支撑。