在人工智能领域,大语言模型(LLM)的演进从未停歇,尽管整体架构自GPT-2以来并未发生根本性变化。近日,Sebastian Raschka博士通过深入分析OpenAI开源的gpt-oss模型(包括120B和20B版本),带领读者回顾了从GPT-2到gpt-oss的技术演进之路,并将gpt-oss与另一开源模型Qwen3进行了详细对比。
8月5日,就在GPT-5发布的前两天,OpenAI宣布推出两款开源大语言模型:gpt-oss-120b和gpt-oss-20b。这是自2019年GPT-2发布以来,OpenAI首次开放模型权重,且得益于巧妙的优化技术,这些模型甚至可以在本地设备上运行。
Raschka博士在其文章《从GPT-2到gpt-oss:架构进步分析》中,详细解析了从GPT-2到gpt-oss的架构演进。他指出,尽管两者在整体架构上相似,但gpt-oss在多个细节上进行了优化,如移除Dropout、采用RoPE替代绝对位置编码、激活函数从GELU转向Swish/SwiGLU等。
首先,Dropout技术虽然在早期Transformer架构中被广泛使用,但现代LLM发现其并不能显著提升性能,反而可能因单轮训练模式导致下游任务表现下降。因此,gpt-oss选择了移除Dropout。
其次,在位置编码方面,gpt-oss采用了RoPE(旋转位置嵌入)替代传统的绝对位置嵌入。RoPE通过对query和key向量施加位置相关的旋转来编码位置信息,这种方式更加高效且逐渐成为LLM的标配。
在激活函数的选择上,gpt-oss从GELU转向了Swish/SwiGLU。Swish的计算成本略低于GELU,且在实践中表现良好,尽管两者在建模性能上的差异并不显著。
更重要的是,gpt-oss对前馈网络模块进行了重构,引入了带门控的GLU(Gated Linear Unit)变体,如SwiGLU。这种结构不仅性能更好,而且总参数量更少,通过门控带来的额外乘法交互增强了模型的表达能力。
gpt-oss还采用了Mixture-of-Experts(MoE,专家混合)技术,用多个前馈模块替代单个前馈模块,并在每个token生成步骤中只启用其中一个子集。这种做法显著增加了模型的总参数量,但通过稀疏性在推理阶段保持了高效率。
在注意力机制方面,gpt-oss引入了分组查询注意力(GQA)替代传统的多头注意力(MHA),并通过滑动窗口注意力进一步降低内存占用和计算成本。同时,gpt-oss还用RMSNorm替代了LayerNorm,以提升训练效率。
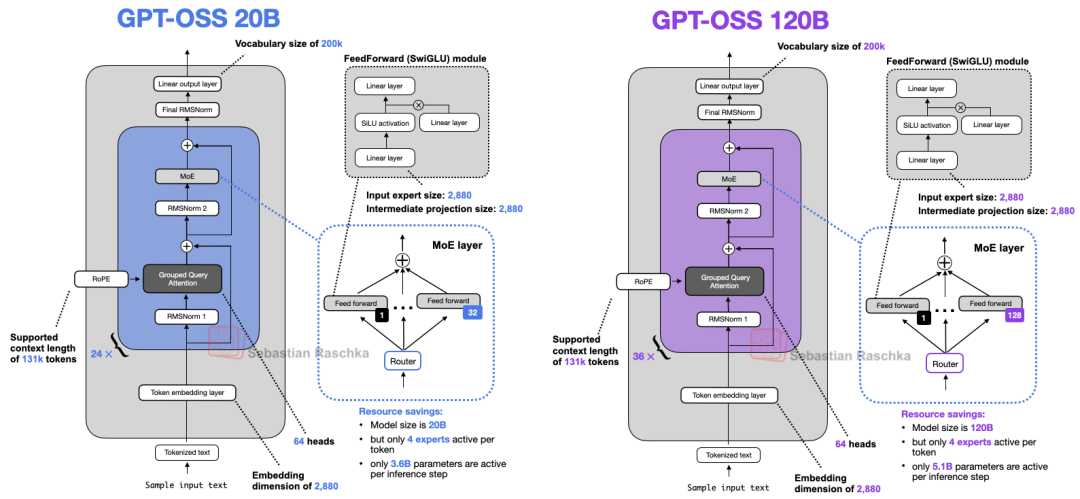
在与Qwen3的对比中,gpt-oss展现出不同的设计思路。Qwen3是一个更深的架构,而gpt-oss则更宽。在MoE的使用上,gpt-oss采用了少量“大专家”策略,而Qwen3则倾向于更多、更小的专家。gpt-oss在注意力机制中引入了偏置项和注意力池,以稳定注意力机制。
在性能方面,gpt-oss与OpenAI自研的闭源模型以及Qwen3相当。尽管gpt-oss在某些任务上可能表现出较高的幻觉倾向,但其作为推理型模型的设计,使其在成本、算力和准确度之间找到了良好的平衡。
随着gpt-oss的开源,更多开发者将能够利用这一强大工具进行本地或私有化部署,推动人工智能技术在各领域的广泛应用。