在科技界的一场盛会上,OpenAI震撼宣布其最新力作GPT-5问鼎巅峰,自诩为全球代码能力最强的AI模型。然而,发布会的高潮却被一场突如其来的尴尬插曲打断——一张对比数据表中,52.8竟然大于69.1等于30.8,这一明显错误迅速在网络上引发热议。
这张原本旨在彰显GPT-5卓越性能的数据表,意外成为了全球网友的笑柄。表中,OpenAI年薪丰厚的精英团队精心准备的数据,却在直播中暴露出了如此低级的错误。尽管随后OpenAI官方迅速更正,但这一插曲无疑为发布会蒙上了一层阴影。
然而,在这场风波之下,一个更为关键的信息却被许多人忽视。GPT-5在SWE-bench Verified基准测试中取得了74.9%的通过率,略高于竞争对手Anthropic的Claude Opus 4.1的74.5%。这一成绩使得GPT-5在软件工程任务基准上暂居领先地位。
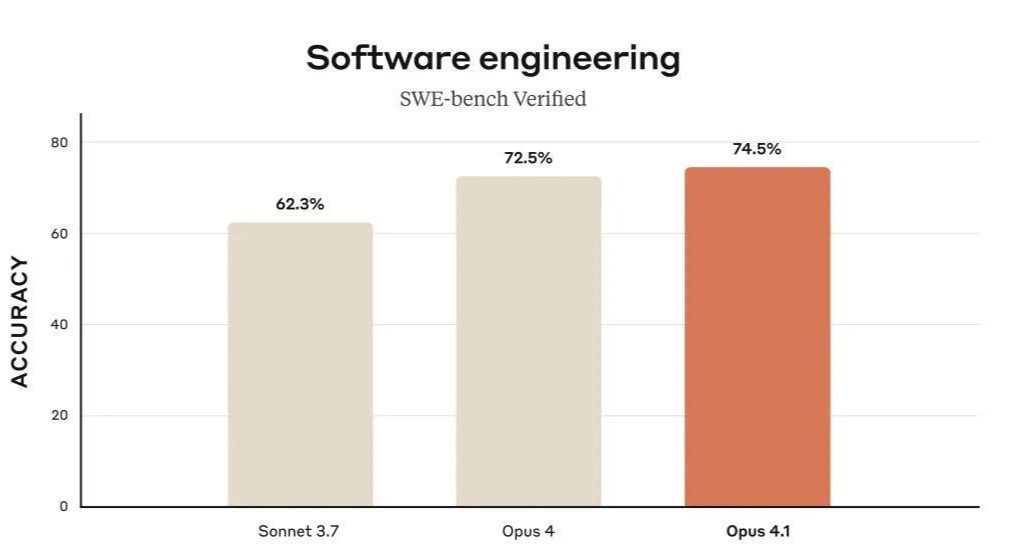
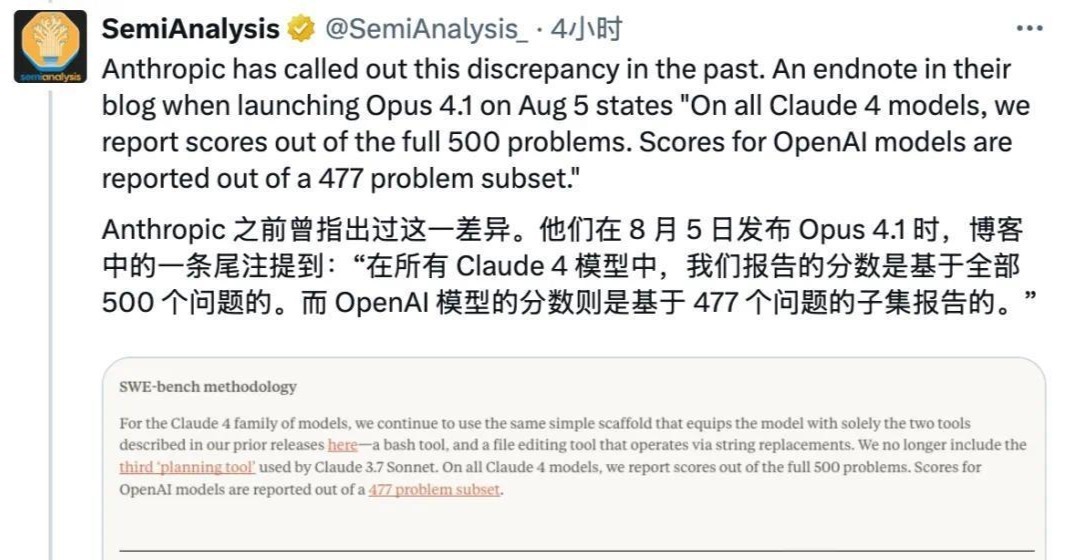
然而,随着事件的深入调查,GPT-5的这一成绩开始显得不那么光彩。原来,SWE-bench Verified基准测试共有500道题目,而GPT-5并未参与全部题目的测试,而是直接跳过了其中23道无法运行的题目,仅基于剩余的477道题目计算得分。
这一发现迅速引发了外界的质疑和争议。SemiAnalysis等专业机构纷纷发帖指出这一问题,Anthropic也在其博客上含蓄地表达了对GPT-5成绩真实性的怀疑。相比之下,Claude Opus 4.1则老实地完成了全部500道题目的测试。
更令人惊讶的是,被GPT-5跳过的这23道题目,恰恰是SWE-bench Verified基准测试中最困难的一批问题。据第三方分析,这些极端困难的任务对模型的综合能力提出了严峻考验,而GPT-5却直接选择了回避。
OpenAI对此的解释是,其基础设施无法运行这23道题目。然而,这一解释并未能平息外界的质疑。如果将这23道题目按0分计入,GPT-5的得分将大幅下降,甚至可能低于Claude Opus 4.1的74.5%。
这场风波的核心争议在于评测分数的可比性和报告方法的透明性。SWE-bench Verified基准测试本身就是由OpenAI与SWE-bench作者合作推出的,因此其公正性和客观性也受到了质疑。SemiAnalysis等机构认为,要想公平地对比模型之间的成绩,或许应该参考SWE-bench官方排行榜上的数据。
SWE-bench被誉为AI界的“程序员高考”,测试题目均来自GitHub上真实的开源项目问题。要想在SWE-bench上取得高分,不仅需要修复bug,还不能引入新的bug,这一标准极为严格。而SWE-bench Verified则是SWE-bench基准测试的一个经过人工校验的子集,其质量更高,难度也更大。
在这场风波中,GPT-5的成绩似乎被人为地“美化”了一番。通过跳过最困难的任务,GPT-5得以在SWE-bench Verified基准测试中取得了一个相对较高的分数。然而,这种做法却引发了外界的广泛质疑和争议。
在科技界,诚信和透明是立足之本。OpenAI作为业界的领军企业,应该更加注重评测的公正性和客观性。希望这场风波能够引起业界的广泛关注,推动评测体系的不断完善和发展。